|
Software systems and computational methods
Reference:
Korchagin V.D.
Analysis of modern SOTA-architectures of artificial neural networks for solving problems of image classification and object detection
// Software systems and computational methods.
2023. ą 4.
P. 73-87.
DOI: 10.7256/2454-0714.2023.4.69306 EDN: MZLZMK URL: https://en.nbpublish.com/library_read_article.php?id=69306
Analysis of modern SOTA-architectures of artificial neural networks for solving problems of image classification and object detection
Korchagin Valeriy Dmitrievich
ORCID: 0009-0003-1773-0085
Postgraduate student, Department of Advanced Engineering School of Chemical Engineering and Mechanical Engineering, Federal State Budgetary Educational Institution of Higher Education "Russian Chemical-Technological University named after D.I. Mendeleev"
127253, Russia, Moscow, Pskovskaya str., 12, room 1, sq. 159

|
valerak249@gmail.com
|
|
 |
|
DOI: 10.7256/2454-0714.2023.4.69306
EDN: MZLZMK
Received:
12-12-2023
Published:
31-12-2023
Abstract:
The scientific research is focused on conducting a study of current artificial neural network architectures in order to highlight the advantages and disadvantages of current approaches. The relevance of the research relies on the growing interest in machine learning technologies and regular improvement of computer vision algorithms.Within the scope of this paper, an analytical study of the advantages and disadvantages of existing solutions has been conducted and advanced SOTA architectures have been reviewed. The most effective approaches to improve the accuracy of basic models have been studied. The number of parameters used, the size of the training sample, the accuracy of the model, its size, adaptability, complexity and the required computational resources for training a single architecture were determined.Prospects for further research in the field of hybridization of convolutional neural networks and visual transformers are revealed, and a new solution for building a complex neural network architecture is proposed.In the framework of the present research work, a detailed analysis of the internal structure of the most effective neural network architectures.Plots of the accuracy dependence on the number of parameters used in the model and the size of the training sample are plotted. The conducted comparative analysis of the efficiency of the considered solutions allowed to single out the most effective methods and technologies for designing artificial neural network architectures. A novel method focused on creating a complex adaptive model architecture that can be dynamically tuned depending on an input set of parameters is proposed, representing a potentially significant contribution to the field of adaptive neural network design.
Keywords:
visual transformers, convolutional neural netwroks, machine learning, analysis, hybrid neural networks, artificial intelligence, computer vision, classification, detection, new method
This article is automatically translated.
Introduction Currently, there is an active popularization of research in the field of development and integration of AI technologies in various spheres of human activity. Artificial neural networks (hereinafter – INS) are becoming a fundamental tool that has a revolutionary impact on many aspects of human life. They have the ability to learn from vast amounts of data, recognize complex images, analyze and formulate forecasts that previously seemed unattainable and provide the opportunity to optimize the performance of everyday tasks by partially or fully automating certain operations. Every year, INS become more powerful and complex, opening up new opportunities in areas such as CV, NLP (from English Natural Language Processing, NLP - natural language processing. Terminology), offline navigation, forecasting and much more. Improving the efficiency of the neural network model is becoming a priority area of research in various ML fields, allowing similar results to be achieved with more economical consumption of computing resources. The purpose of this article is to conduct a study of modern INS architectures used to solve problems of object classification and detection. The main focus of the research is aimed at identifying the most effective methods in the INS structure by comparative analysis of their advantages and disadvantages. The article will review the historical development of recent architectural achievements, provide a detailed description of the key aspects underlying modern approaches in the field of CV, review current trends and challenges faced by researchers and engineers working with AI technologies, and present comparative graphs demonstrating the main performance indicators of modern INS models. The results obtained will allow us to identify the common advantages and disadvantages of modern approaches to the construction of neural networks, to determine the prospects and directions of future research. As it is known [1,2,3], the internal structure of the INS is a complex mathematical model containing many variable parameters and dynamically changing computational blocks. Regardless of the depth of the model and the complexity of the approaches used, the general architectural representation of the INS can be illustrated as follows (Fig. 1). 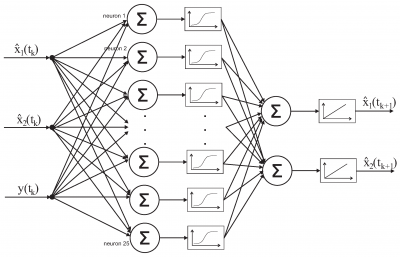 Fig. 1 – Diagram of the neural network architecture in general form where x and y are neurons or features of the input layer, ? is the summator of the weighting coefficients obtained from the input set of features, the graph reflects the activation function to maintain the linearity or nonlinearity of the output results In addition, INS are classified according to various criteria, including the number of computational layers and the type of building internal connections between neurons: single-layer, multi-layer and feedback. However, regardless of the class used, the basic structural elements inherent in any INS model are preserved. Any differentiable solution can be used as an activation function [4,5]. The determination of the most appropriate dependence is carried out by a data engineer based on: a deep analysis of the subject area and the choice of an activation function with an optimal distribution character, existing experience in solving a similar set of tasks, a selection method to achieve the most accurate indicators of model convergence. After selecting the activation function, the computational processing stage follows. The input data is fed to the neural network in the form of a tensor containing a certain set of parameters [6]. Further, depending on the current stage of model construction, either unidirectional direct propagation of the error occurs, if the model is ready for use in real tasks, or bidirectional (forward and reverse) propagation of the error, if the model is found in the learning process. In the process of direct propagation, the sum of the input signals is calculated taking into account the weighting coefficients for each connection, then an activation function is applied to obtain the output values. In the process of learning the model, the final result is analyzed in accordance with the chosen teaching method - with a teacher, without a teacher, or with reinforcement. The differences between the methods are in the way to get an answer about the correctness of the received prediction. The purpose of INS training is to minimize the loss function by updating the weight coefficients in the direction of the anti-gradient at each step of training using variable gradient descent algorithms. The gradient value is calculated by determining the partial derivatives of the weighting coefficients. The learning process by updating the weighting coefficients in accordance with the established step in the direction of the anti–gradient vector is called backpropagation (from the English backpropagation, backprop is the reverse propagation of the error. Terminology) and continues until the threshold value of the accuracy value is reached, or until the specified number of training epochs has passed. The main difference between more complex models lies in the scale of the input parameter space used, which allows you to create more complex dependencies, aggregating a more extensive set of features and contributing to the processing of both structured and unstructured data of a larger volume. In addition, modern progressive INS models use a multi–layered backbone structure (from the English backbone - skeleton, spine. Terminology), which allows you to identify both general and more local dependencies within a single dataset. For example, in the context of image recognition, a multi-layered architecture can be used to highlight and concatenate various image patterns. Advanced INS have a number of common problems, the solution of which contributes to the dissemination of research and the integration of new approaches in the field of ML and AI technologies. These include: – A large number of input parameters. In the context of image processing and analysis, there is a directly proportional increase in the size of the model, depending on the resolution and the number of color channels. As a result, the use of the basic INS architecture for the analysis of modern high-quality images becomes inapplicable due to a significant increase in both training time and processing of the input data set; – Retraining. It represents an alternative problem related to the size of the model. An increase in the number of neurons in the INS contributes not only to an increase in the time duration of learning, but also to an improvement in the ability of the model to memorize signs. When training on a limited amount of data, the INS can achieve the minimum values of the loss function, which indicates an ideal prediction within the training sample. However, when testing on a real set of test data, the network may show a significant increase in the proportion of erroneous values compared to the results on the training sample. This phenomenon characterizes the unsuitability of the obtained model for the effective solution of the task, since, instead of generalizing the dependencies in the data, a specific training set is memorized, including both structured and “clean” data, and random, noisy or abnormal samples. As a result, the model may demonstrate a weak ability to predict reliable results in practice;
– Attenuation of gradients. It is a common phenomenon in the context of INS training. This problem is related to the fact that the values of the partial derivatives of the loss function according to the parameters of the model. Calculated in the backprop process, over time, can take on anti-gradient values at the error level. As a result, the INS demonstrates a sharp decrease in the speed of learning and updating weight coefficients, which also characterizes the unsuitability of the model for use in real tasks. The solution of the presented ensemble of problems contributes to the development of more flexible and efficient architectural approaches that allow achieving similar or higher performance with a more economical consumption of computing resources. Therefore, the study of modern INS architectures is an urgent task, which allows us to obtain information about the most successful approaches used in practice. Materials and methods of research To analyze the latest advances in machine learning architectures, it is necessary to familiarize yourself with the comparative graph of the most effective models used in classification and detection tasks in recent years. When selecting the most effective models, only the final iterations of State-Of-The-Art (hereinafter referred to as SOTA) architectural solutions were taken into account. The analysis is based on the results obtained using the following datasets: ImageNet, CIFAR-10, CIFAR-100, MS COCO-minimal. Information about the used datasets was taken from the open research portal PapersWithCode. To carry out the analysis, a set of five SOTA models from each dataset was formed. Figure 2 shows the summary performance indicators of the INS models, divided into groups depending on the dataset used and the metric used. 
Fig. 2. Summary results of the effectiveness of the INS models A comparative analysis of the effectiveness of the INS will be based on the following set of basic criteria: – Classification accuracy: the ability of the model to correctly classify the data presented to it; – Model size: the number of parameters in the INS architecture that affect its size and the ability to deploy in conditions of limited computing resources; – Adaptability: the ability of the model to produce the correct result when introducing a new, erroneous or modified set of input data. This parameter will be evaluated based on information about the size of the training sample and the accuracy of the classification. Also, when evaluating the effectiveness of the most successful approaches, the following set of parameters will be implicitly taken into account: – Learning and prediction speed: It is determined by the time spent on training the model and making predictions. It is an important factor when analyzing a larger data set or solving problems in real time; – Resistance to retraining: an indicator reflecting the ability of the INS to generalize the data of the training sample; – Versatility: the ability of the model to work with various types of tasks, such as classification, detection, clustering, and others; – Model complexity: This criterion is related to the number of layers and neurons in the architecture, affecting learning and performance. Conducting an actual comparison of these parameters is not possible due to the lack of recorded information in most existing solutions. The aggregation of the above criteria forms a comprehensive assessment of the effectiveness of the INS, which is important when choosing a model for solving a specific range of tasks. This article provides an analysis of the most effective approaches demonstrating a significant increase in efficiency compared to previous architectures based on a study of the relevant literature [7-33]. Let's consider the structural components of each of the most effective solutions. SENet[7] is an innovative solution in which the SE block (from the English Squeeze and Excitement, SE - compression and excitation) was developed in order to establish clear links between feature channels based on global spatial information. The squeeze block is formed by applying the GAP operation (from the English Global Average Pooling, GAP – global average pooling) to the original feature map, which creates a one-dimensional vector containing the average statistical values for each channel. To use the information obtained at the compression stage, an Excitement block is used, the essence of which is to use the gating mechanism (from the English gating – gating, transmission. Terminology) through the sigmoids function to highlight the most significant element in the intermediate dataset. To limit the complexity of the model, the parameterization of the gating mechanism is performed using a bottleneck (from the English bottleneck – a bottleneck, a narrow neck. Terminology), consisting of two FC layers (from the English Fully Connected, FC – fully connected. Terminology), separated from each other by the activation function of ReLU, which is a layer with a dimensionality-lowering coefficient. Additional methods for improving accuracy are ShakeShake [8] and Cutout[9] regularization. Regularization is the addition of additional information to the model in order to prevent overfitting and reduce the impact of "noise". It is achieved by adding penalties or constraints to the loss function of the underlying model. According to the results of the study [7], the integration of the developed SE block into the ResNet architecture [10] allows to increase the accuracy of the ANN, on average, by 10%, depending on the depth of the model with a relatively small increase in computational costs. In addition, the authors argue that the selection of the reducing coefficient should be carried out manually, based on the requirements of the basic architecture, since, depending on the value of the coefficient, the number of parameters decreases, which may affect the accuracy of the model, as evidenced by the comparison results using the example of the SE-ResNet-50 model [7]. It is noteworthy that the computational complexity of the deepest ResNet-152 model using the SE block has a value of 11.32GFLOPs, while the result of the original model is 11.3GFLOPs. EfficientNet [11] (abbreviated EffNet) is an architectural embodiment of a deep neural network based on the technology of generative construction of an adaptive architecture similar to that used in MnasNet. The key idea and difference between EffNet and MnasNet is that, according to the authors [11], the dimension of the convolutional layer extracting features from the image has a linear dependence on the size of the input image, which requires changing the depth, width of the convolutional layer or image resolution to extract more "subtle" patterns. Unlike traditional methods [11], the author's approach consists in the combined application of all traditional methods. Additionally, it was found that changing the hyperparameters of the model has a heterogeneous effect on computational complexity. Increasing the depth of the model by adding new convolutional layers has a linear dependence of computational complexity, while increasing the filter width or image resolution has a quadratic effect.
Based on the results of 2017 research by Google specialists [12], an approach was applied to the construction of recurrent neural networks to create an autonomously generated model. The principle of operation of the MnasNet architecture is to predict the most effective block of width, depth or stride for a given tensor (Compound Scaling method), build a model and then train with reinforcement by maximizing the reward value. Based on the classification results, the error gradient is projected into the initial building block of the INS and repeated prediction is made. The authors of the study [12] note that iterative repetition continued until a given number of learning epochs were reached, but this approach can be repeated an unlimited number of times. Using the concept of multi-purpose search, optimizing both accuracy and computational complexity, the proprietary basic architecture of EffNet-B0 was developed. The main element of the entire architecture is an inverted bottleneck block, called MBConv in combination with the previously mentioned SE block concept [7]. The scaling of the INS takes place in 2 stages: – Stage 1. The authors fix the parameter ? = 1, it is assumed that there is a twofold excess of free resources, after which a search is performed on a small network ?, ?, ? based on expressions 7 and 9. For EffNet-B0, the best coefficient values were ? = 1.2, ? = 1.1, ? = 1.15, taking into account the following limitation ?*? 2*? 2 ?2. – Stage 2. The variables ?, ?, ? are fixed as constants, after which the network is scaled according to various parameters using expression 9. Thus, EffNet modifications from B1 to B7 were obtained It is important to note that using the Compound Scaling method is effective only for basic models with a small number of parameters. Increasing the size of the model significantly reduces efficiency and slows down the process of finding optimal solutions [11]. The general idea of sequentially generating the building blocks of the INS model is called AutoML. However, the main limitation of this approach is the use of predefined convolutional operations, relationships, and block structures. Therefore, full automation of the process of searching for the optimal architecture is not possible within the AutoML approach. ViT. Visual Transformer architecture [13]. Since a distinctive feature of all ViT models is the complete uniformity of the structure, with the exception of the size of the receptive field, the analysis can be produced for all existing models simultaneously. The idea of ViT arose after the success of the Transformer architecture in NLP tasks. Transformer [14] is based on the encoder-decoder structure used to transform sequences. Basically, to solve NLP tasks, the transformer uses the mechanism of multi-head attention (from the English Multi–Head Attention, hereinafter referred to as MHA). This mechanism is based on the method of scaled product of scalars (multiplicative) (from the English Scaled dot-product attention), which is a weighted sum of matching a query with key-value pairs. NLP uses the results of word tokenization as input parameters. Instead of using a single attention function with all keys, values and queries of the model dimension, the authors [17] decided to apply linear projection of keys and values h times with learned projections of dimensions D k, D k and D v. On each projection, an attention function is performed in parallel, the result of which is the output values of dimension D v.MHA allows you to use information from different subspaces at different positions. In addition to the layers of attention, the FC layer of direct propagation is applied piecemeal to each position. To generate a probabilistic distribution of the subsequent token based on the decoder output, a linear transformation operation is used in combination with a softmax function. Since the use of explicit tokenization in CV tasks is impossible due to the high demands on computing resources due to a large number of parameters and the quadratic dependence of the operating time of the attention mechanism on input data, the ViT architecture uses a combined approach based on patching (from the English Patch – patch. Terminology) and PE (from the English Position Embedding, PE – embedding a position). The patching mechanism is performed by splitting a complete set of pixels into small groups known as patches. The resulting set of tokens is fed into the standard encoder of the Transformer architecture [14] together with the class-token, which is used for the final classification of the image followed by a block of the direct distribution network. Swin-V2. As previously noted, the attention mechanism has a quadratic dependence on the input set of tokens, which calls into question the applicability of ViT for segmentation or detection tasks due to the need to use patches of a smaller dimension, which will immediately have a significant negative impact on network performance. The Swin architecture [15,16] represents the next stage in the development of visual transformers for the tasks described above. A set of patches of dimension 4*4 is received at the input, after which several layers of Batch Merging (hereinafter referred to as PM) and Swin Transformer Block (hereinafter referred to as ST) are sequentially applied through a linear transformation. PM performs the operation of concatenating the features of neighboring tokens in a 2*2 dimension filter, obtaining a higher-level representation of the image. Thus, after each stage, a feature map of various hierarchical representations is formed, after which the ST block is applied. A study of the structure of the ST block shows [15,16] that it reflects the classical encoder-decoder architecture [14], but differs in the use of skip-connection operations characteristic of ResNet and the modified attention function, which is a key element of the Swin architecture. The authors [15,16] decided to consider attention not with all tokens existing in the set, but only with those that are in a certain area of fixed size ((Window) Multi-Head Self Attention, hereinafter – W-MSA) Thus, attention now functions in linear hw time. However, the use of this method is accompanied by a decrease in the representative capacity of the network due to the lack of communication between different tokens. To correct this problem, the authors added an additional layer with a diagonal offset of the receptive window after each block of W-MSA. This restored the interaction between tokens while maintaining linear computational complexity. Due to the increase in the number of computational operations, when using this approach, the authors proposed conducting a preliminary cyclic shift in order to exclude interaction between non-adjacent tokens by applying a mask. This approach allows you to save the number of attention operations when applying the image padding operation. In addition to introducing a new Attention calculation method, the authors introduced a new position embedding calculation by adding a trainable relative position bias matrix. As a result of the synthesis of RA and W-MSA, it became possible to build an architecture that allows extracting features at different spatial scales and successfully using Swin as a backbone in segmentation and detection tasks.
CoAtNet-7. The Convolutional Attention Network [17] is the result of a combination of advanced CNN and ViT approaches for solving CV problems. By combining spatial convolution and the self-attention mechanism, as well as sequentially overlaying layers of convolution and attention, an architecture has been developed that exhibits high performance on both large and small datasets. CoAtNet introduces a new structure of relative attention (from the English relative attention, hereinafter – RA), which integrates the concept of relative weights or offsets into the process of encoding and decoding data. Instead of assigning fixed weights to each element, RA allows the model to take into account the relative positions of elements in the sequence when calculating weights. This is especially useful when the importance of the elements depends on their relative location rather than absolute. However, using RA to the original image requires significant computational costs. The authors [17] conducted a study of two approaches to solving this problem: – Using a 16*16 convolutional stem block, followed by L-transformer blocks with RA; – The use of a multi-stage network with gradual pooling. 4 network configurations were selected for the study, consisting of a C-convolution and a T-transformer. The assessment was based on two criteria: – Generalization: the value of the minimum gap between the indicators for the training and validation sample; – Capacity: Best performance in the same number of epochs. The result of the author's research was the conclusion that the use of C-C-T-T construction is the most effective among the studied. Results For a comprehensive assessment of the effectiveness of the available solutions, it was necessary to analyze the dependence of the accuracy of the model on the number of parameters and the size of the training sample. To do this, we used data from previously described models trained on the ImageNet dataset. In the absence of data for a specific model, it was excluded from the resulting sample. A graphical representation of the normalized results of the study is illustrated in Figure 3. 
Fig. 3 – Graph of the normalized ratio of parameters Based on the analysis of the information provided, it can be argued that convolutional architectures currently have higher efficiency compared to hybrid or ViT solutions. From the point of view of the ratio of accuracy, the size of the training sample and the number of parameters, the most effective architecture is EfficientNet from the CNN family. It shows a high ability to generalize data in classification tasks with a small training sample and a number of model parameters. In addition, modern solutions based on the ViT architecture or using a hybrid approach require more data to achieve record-breaking or CNN-like results. However, the study [13] indicates a high learning rate of ViT solutions due to the ability of patches to cover the entire receptive field of the image simultaneously, in contrast to the sequential comparison of output feature maps in CNN architectures. According to the results of the study [13], the use of CNN and ViT hybridization allows, on average, to achieve greater classification accuracy with equal computational complexity, as evidenced by the illustration in Figure 4. 
Figure 4 - Comparison of computational complexity of CNN, ViT and hybrid approach Based on the analysis of the above factors, it can be concluded that currently the most effective building blocks for building an INS architecture are: AutoML + Compound Scaling (EffNet, CNN), W-MSA (Swin-V2, ViT), Squeeze and Excitement (SENet, CNN), Skip-connection (residual blocks, ResNet, CNN). Further research is aimed at improving existing architectural solutions by developing a hybrid CNN-ViT architecture in order to reduce the dependence of the learning rate and accuracy of the model on the size of the training sample. This result can be achieved through the integrated application of AutoML, Compound Scaling, and EffNet backbones technologies, or by developing the latest approach to extracting features from the input dataset. The obtained research results can be used to select the optimal architecture for building an INS that solves specific business problems or to develop an innovative model that takes into account all the above-mentioned performance criteria.
References
1. Gomolka, Z. (2017). Using artificial neural networks to solve the problem represented by BOD and DO indicators Water, 10(1), 4.
2. Kadurin, A., Nikolenko, S., & Arkhangelskaya, E. (2018). Deep Learning. Immersion in the world of neural networks. Sankt-Petersburg "Peter".
3. Dzhabrailov, S. V. O., Rozaliev, V. L., & Orlova, J. A. (2017) Approaches and realizations of computer simulation of intuition. Bulletin of Eurasian Science, 2, 39.
4. Babushkina, N. Ĺ., & Racgev A.A. (2020). The choice of the neural network activation function depending on the task conditions. Innovative technologies in mechanical engineering, education and economics, 27, 2, 16, 12-15.
5. Sosnin, A. S., & Suslova, I. Ŕ. (2019). Neural network activation functions: sigmoid, linear, step, relu, tahn. BBK, P. 237.
6. Bredikhin, A. I. (2019). Algorithms of training convolutional neural networks. Bulletin of YSU, 1, 52.
7. Hu J., Shen L., & Sun G. (2018). Squeeze-and-excitation networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 7132-7141.
8. Gastaldi, X. (2017). Shake-shake regularization.arXiv preprint arXiv:1705.07485.
9. DeVries, T., & Taylor, G. W. (2017). Improved regularization of convolutional neural networks with cutout.arXiv preprint arXiv:1708.04552.
10. He, K. (2016). Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, P. 770-778.
11. Tan, M., & Le, Q. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks. International conference on machine learning, 6105-6114.
12. Tan, M. (2019). Mnasnet: Platform-aware neural architecture search for mobile. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2820-2828.
13. Dosovitskiy, A. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
14. Vaswani, A. (2017). Attention is all you need. Advances in neural information processing systems, 30.
15. Liu Z. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. Proceedings of the IEEE/CVF international conference on computer vision, P. 10012-10022.
16. Liu, Z. (2022). Swin transformer v2: Scaling up capacity and resolution. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, P. 12009-12019.
17. Dai, Z. (2021). Coatnet: Marrying convolution and attention for all data sizes. Advances in neural information processing systems, 34, 3965-3977.
18. Zhai, X. (2022). Scaling vision transformers. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, P. 12104-12113.
19. Huang, Y. (2019). Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32.
20. Emelyanov, S. Î.,Ivanova, A. Ŕ., Shvets, E. Ŕ., & Nikolaev, D. P. (2018). Augmentation methods for training samples in image classification tasks. Sensor Systems, 32(3), 236-245. doi:10.1134/S023500921218030058.
21. Cubuk, E. D. (2019). Autoaugmentation: Learning augmentation strategies from data. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 113-123.
22. Han, D., Kim, J., & Kim, J. (2017). Deep pyramidal residual networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 5927-5935.
23. Yamada, Y.(2019) Shakedrop regularization for deep residual learning. IEEE Access, 7, P. 186126-186136.
24. Kolesnikov, (2020). Big transfer (bit): General visual representation learning. Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part V 16.-Springer International Publishing, 491-507.
25. Foret, P. (2020). Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412.
26. Pham, H. (2021). Meta pseudo labels. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11557-11568.
27. Yu, J. (2022). Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917.
28. Chen, X. (2023). Symbolic discovery of optimization algorithms. arXiv preprint arXiv:2302.06675.
29. Zhang, H. (2022). Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605.
30. Yang, J. (2022). Focal modulation networks. Advances in Neural Information Processing Systems, 35, 4203-4217.
31. Wang, L. (2021). Sample-efficient neural architecture search by learning actions for monte carlo tree search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9), 5503-5515.
32. Wang, W. (2023). Internimage: Exploring large-scale vision foundation models with deformable convolutions. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, P. 14408-14419.
33. Zong, Z., Song, G., & Liu, Y. (2023). Detrs with collaborative hybrid assignments training. Proceedings of the IEEE/CVF international conference on computer vision, 6748-6758.
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The article deeply analyzes modern architectures of artificial neural networks (ANNs), focusing on their use in image classification and detection tasks. The authors effectively identify the area under study, emphasizing the importance of INS in the current scientific discourse. The study is based on an integrated approach, including the analysis of data from various sources and a comparative analysis of the effectiveness of various INS architectures. This approach demonstrates a deep understanding of the subject and allows the authors to reach meaningful conclusions. The research topic is extremely relevant, given the growing importance of AI technologies in the modern world. The study highlights the importance of developing and optimizing the INS to improve analytical capabilities in the field of image processing. The article presents a new look at the analysis and comparison of modern INS, enriching the scientific community with fresh ideas and approaches. The authors stand out for their original analysis and interpretation of the data, which contributes to the advancement of scientific understanding in this field. The article is characterized by a clear structure, logical presentation and high-quality writing style. The text is organized so that the reader can easily follow the logic of the authors and their arguments. The extensive and up-to-date list of literature testifies to the careful work of the authors on the study. The use of authoritative sources increases the reliability and scientific value of the work. The authors adequately relate to existing views and research in this field, providing respectful and constructive criticism, which contributes to the development of dialogue in the scientific community. The conclusions of the article are convincing and well supported by the presented data and analysis. The research is of considerable interest to a wide range of readers, including specialists in the field of computer vision, artificial intelligence and machine learning. The analysis of the research results highlights the importance and effectiveness of the presented INS architectures, especially in the context of image processing and analysis. The authors demonstrated a deep understanding and analysis of various architectures, including convolutional models, transformers and hybrid systems. They effectively compared them according to criteria such as classification accuracy, model size, adaptability, learning speed, resistance to overfitting, versatility and complexity of the model. This comprehensive analysis provides valuable information about the advantages and disadvantages of each approach, which is important for researchers and practitioners in the field of artificial intelligence and machine learning. In general, the results of the study demonstrate a significant contribution to the development and understanding of modern INS architectures, providing practical recommendations for their selection and application in real-world tasks. These results highlight the relevance and importance of the study, making it a significant contribution to the field. In addition to the positive review, I would like to note that the drawings in the article go beyond the boundaries of the HTML page, which can make it difficult to view and perceive them. It is recommended to present the illustrations more succinctly in order to ensure their better visual accessibility and integration with the text of the article.
|








