|
DOI: 10.7256/2454-0714.2023.1.38483
EDN: ANMSZI
Received:
19-07-2022
Published:
28-01-2023
Abstract:
The emergence of multicore architectures has extremely stimulated the area of parallel computing. However, developing a parallel program and manually paralleling inherited sequential program codes are time-consuming work. The programmer should have good skills in using parallel programming methods. This fact determines the relevance of the subject of the research – the development of a serial-to-parallel code translator. The article gives a review of existing solutions in the chosen direction of research and considers their advantages and disadvantages. The principle of formation of a syntactic tree which is based on JSON format (the text format of data exchange based on JavaScript) is offered and an example of formation of a syntactic tree on the basis of this principle is considered. The result of the work is an approach for building a program platform for translating sequential code into parallel code. The distinctive feature of the developed platform is the web-service, which potentially allows you to extend the translator with other programming languages. The interaction with the programming environment is realized by means of REST-requests (HTTP-requests designed to call remote procedures). The developed software platform consists of three modules: the query processing module, which provides interaction with external systems through REST-requests; the tree building module, which forms a syntax tree on the basis of the source program code; the code conversion module, which obtains parallel program code on the basis of the syntax tree.
Keywords:
multicore processors, parallel computing, parallel programming, multithreaded programming, automated translator, JSON format, programming languages, syntax tree, web service, REST requests
This article is automatically translated.
IntroductionRecently, in order to improve the performance of computing systems, there has been an increase in the number of multiprocessor complexes that allow operating with a large amount of computing. To solve computationally complex problems in an acceptable time, the development of software modules using multithreaded programming is required. To write parallel programs, highly qualified programmers are needed: an analyst, a programmer, and a testing specialist are required to participate in the work. Companies incur significant financial costs by paying for the work of IT specialists of this class. Specialized languages, such as Cilk, are useful for parallel programming. Using this language, it is possible to provide function calls asynchronously until the synchronization point is reached in the parent function. This style of parallelism is called divide and conquer, or fork-join parallelism. In it, the program is divided into smaller tasks that are planned for parallel execution. In addition to Cilk, there are specialized libraries, for example, Java Fork Join. Often, due to the complexity of debugging, a programmer initially has to write a sequential (single-threaded) program, and then adapt the solution into a parallel (multithreaded) equivalent. Therefore, the question of automated (or automatic) conversion of serial code into parallel is relevant. Automatic conversion does not require human intervention, but is accompanied by a number of difficulties in achieving an unambiguous solution (sequential code may have various parallel equivalents). An automated translator uses a dialogue with a programmer to clarify the properties of a serial program in order to obtain the best parallel equivalent, which is thread-safe and optimized for the use of hardware resources and performance criteria. Currently, there are no programs that allow you to successfully cope with automatic parallelization. This is due, for example, to the presence of nested functions in programs, complex expressions for the formation of cycles, which complicate the analysis of data dependencies. The most well-known software products implementing the automated approach are [1,2]: Parawise, Polaris, Cetus, Pluto, Polly, Par4All, CAPO, WPP, SUIF, VAST/PARALLEL, OSCAR, SAPPHIRE. Let's conduct a comparative analysis using the example of Parawise. Let's consider the steps of the algorithm responsible for converting serial to parallel code in the Parawise software product (see Fig. 1): - Getting a sequential code.
- Analysis of serial code dependencies based on user data and recording of information in the database.
- Splitting the input code into tokens (objects created from a token in the process of lexical analysis, for example, “{”, “}”, “ case”, “do”, “else”, “for”, “if”, “sizeof”, etc.) and recording information in the database with the participation of the user.
- Control of masks (control of maximum and minimum values for conditions) and recording of information in the database with the participation of the user.
- Calculation and generation of the syntax tree structure and recording of information in the database.
- Code optimization (reducing memory usage) and writing information to the database.
- Code generation and the transition to the next section of the code in paragraph 3, or the formation of the result of converting serial code into parallel code.
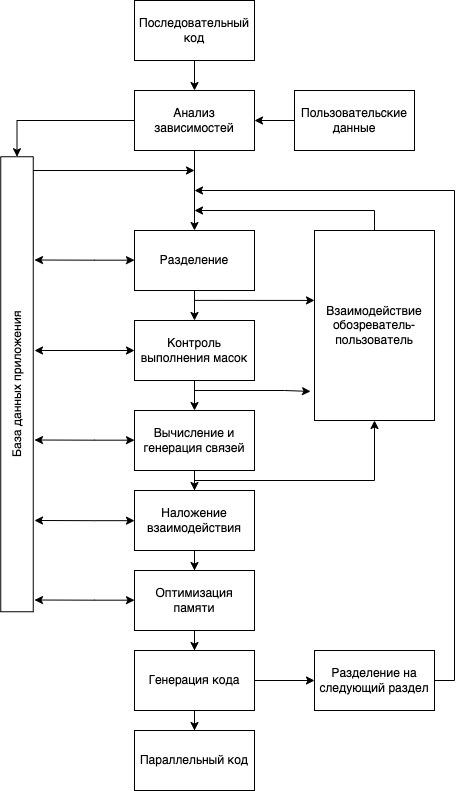
Figure 1. Parawise algorithmFigure 2 shows the steps for converting serial code into parallel code for the CAPO software product. Figure 2. CAPO operation algorithm 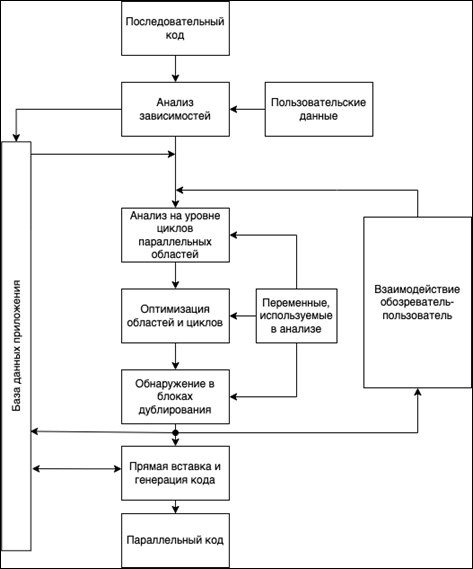
- Getting sequential code that needs to be parallelized.
- Analysis of dependencies in the received sequential code with the processed user data and data entry in the database.
- Based on input dependencies, DB, user interaction data and variables used in the analysis, the analysis is formed at the level of parallel domain cycles.
- Optimization of areas and cycles based on analysis at the level of cycles of parallel areas and variables used in the analysis, the formation of optimization of areas and cycles.
- Based on the data obtained, duplication in blocks is detected. Intermediate data is entered into the database and the user is interviewed for data correction.
- Performing direct insertion of the received data, code generation, data exchange with the database.
Note that Parawise and CAPO work according to a similar algorithm, as do the programs Cetus, Pluto, Polly, Par4All, CAPO, WPP, SUIF, VAST/PARALLEL, OSCAR, SAPPHIRE. One of the disadvantages is that these software products are desktop, i.e. they are dependent on the target platform (they cannot be run on different operating systems), and it is also required to monitor software updates. Separately, the user interaction block should be highlighted, in which the user selects the required solution. The implementation of this block, presented in CAPO and Parawise, eliminates the possibility of automatic parallelism. This requires the programmer to have knowledge in the field of parallel programming [3,4]. The approach proposed in the article allows us to switch to automating the translation of parallel program code with the least operator involvement, since the user interaction unit is self-learning, based on deep learning [5,6]. Translator Architecture When developing a translator that allows you to convert serial code into parallel, it was decided to make a web application. This decision is caused by the following factors: - the web application does not require installation;
- all updates occur on the server, are delivered to the user immediately (it is enough to reload the web page);
- The web application is accessible from anywhere in the world, from any device, and user files will always be at hand if there is an Internet connection.
The translator project has a microservice architecture (Fig. 3). The application consists of several programs (services): - request processing service (request handler),
- syntax tree building service,
- code conversion service,
- the database is based on the PostgreSQL DBMS.
The request processing service allows you to accept user REST requests, namely a request to convert serial code into parallel [7,8]. The request specifies the sequential code required for parallelization, as well as the programming language in which it is written. The service also allows you to make queries to the database to get data about the syntax tree and the transformed code. 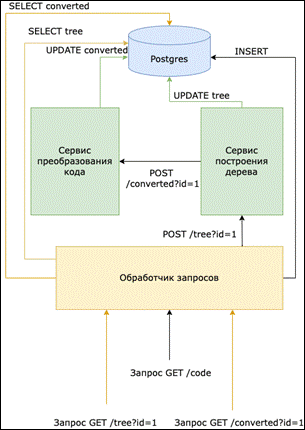
Figure 3. Translator architecture The tree building service converts sequential code into a syntactic tree. Writes data about the syntax tree to the database, after writing data to the database, sends a request to complete the construction of the syntax tree to the code conversion service. Parallel Program generation services The code conversion service takes data about the constructed syntax tree from the database, builds various parallelization schemes for the source program. Next, the constructed scheme is evaluated according to a set of rules obtained from the database corresponding to the syntax of the text conversion language from the syntax tree, and builds the program text using the principles of parallel programming and writes it to the database [9, 10]. The creation of a parallel program can be viewed in the sequence diagram (Fig. 4). We will give a description of this diagram. 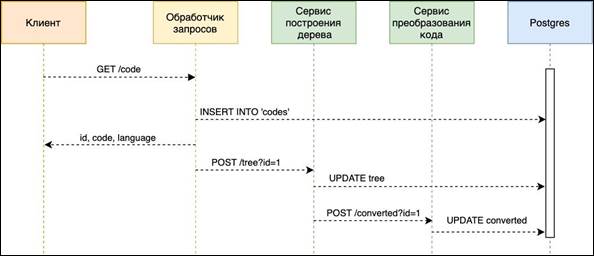
Figure 4. Diagram of parallel program creation sequences The client sends a REST (GET ‘/code') request to convert serial code to parallel. The query processor inserts new data into the database code table and gets the ID value of the new field. The next step is for the request handler to send data about the recorded identifier to the syntax tree building service by POST request. The tree building service receives data about the sequential code from the database and converts it into a syntactic tree. The result of the conversion is recorded in the database and transmitted to the code conversion service by a POST request with an identifier. The code conversion service converts the syntax tree into parallel code and writes it to the database.
The program is built in accordance with the microservice architecture. As a plus of microservices, we can highlight the availability of additional features for adding new program functionality to work with other languages: adding a syntax tree or converting to parallel code. In case of a greater load on the part of users, a RabbitMQ or Kafka message broker is added, which allows converting a message (for RabbitMQ – AMQP, Kafka – Kafka protocol) from the source application to the receiver application, thereby acting as an intermediary between them. In this case, the client sends a request to convert the code to the request handler service. The query processor writes data to the database, sends code to the message broker with an identifier and a programming language that needs to be converted into a syntax tree. The tree building service transforms the syntax tree into the required code for a given programming language. After that, data is recorded in the database and the identifier and name of the programming language are sent to the message broker (a system that converts a message from the data source “producer” into a message from the receiving party “consumer"). The code conversion service via a message broker converts the code into a parallel equivalent of the required programming language. 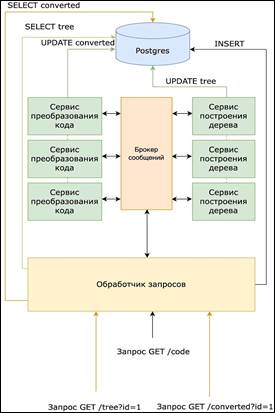
Figure 5. Translator architecture using a message broker 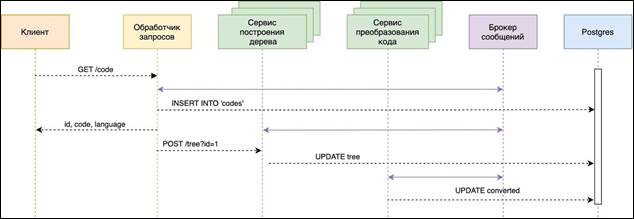
Figure 6. Diagram of the sequences of creating a parallel program using a message broker Building a syntax tree During the design, various syntax tree formats were considered. The most popular is ANTLR4, a lexical analysis library for Another Tool for Language Recognition (ANTLR). The principle of operation of ANTLR is based on the syntactic analysis of the input data stream, building a syntax tree, traversing this tree and providing a generated API for implementing logic for each of the traversal events. The API is generated based on a “grammar” that defines the structure of a sentence, individual phrases/words and specific symbols. However, this library has been written for a long time, as a result of which it lacks support for modern programming languages and requires additional libraries at runtime. The next common syntax tree format is Babel AST. The disadvantages of this format include the lack of support for the C programming language and a large amount of transmitted data. Based on the identified shortcomings of the considered solutions, it was decided to develop a syntax tree with its own format. The developed syntax tree is characterized by the following stages: - Lexical analysis of the input program. This process is characterized by analytical analysis of the input sequence of characters into recognized groups – tokens – in order to obtain identified sequences called "tokens" at the output (similar to grouping letters in words).
- Syntactic analysis or syntactic parsing is the process of matching a linear sequence of lexemes (words, tokens) of a natural or formal language with its formal grammar.
- Semantic analysis is applied to the resulting structure, the process of identifying the "meaning" of syntactic constructions. An example is associating an identifier with its declaration, data type, definition of the resulting expression data type.
- Next, the conversion is performed to intermediate code (in our case, this is code in JSON format).
Let's look at a simple example of conversion to a syntax tree. We send a JSON parcel with a sequential code to the input: {
"code": "int main()n {n for(int i=0; i<=4; i++)n{n printf("Text"); n} n return 0;n}",
"language": "C"
}Where code is sequential code intended for parallelization; language is the programming language in which the code is written.
We get the formed syntax tree:
{ "tree": [
{
"type": "Program"
},
{
"type": "FunctionDeclaration",
"typeVar": "int",
"id": "main",
"params": [],
"body": [
{
"type": "ForStatement",
"init": [
{
"type": "VariableDeclaration",
"id": "i",
"value": "0",
"variable": "int"
},
{
"type": "CompareExpression",
"id": "i",
"mark": "<=",
"number": "4"
},
{
"type": "UpdateExpression",
"id": "i",
"operator": "++",
"prefix": "false"
}
],
"body": [
{
"type": "StringFunctionDeclared",
"value": "Text"
}
]
},
{
"type": "ReturnStatement",
"argument": {
"type": "Literal",
"value": "0"
}
}
]
}
]
}Description of the fields used: tree – the root tree of the project; - type – the type of the described block;
- TypeVar – data type;
- id – the name of the identifier;
- params – parameters of the described object;
- body – the body of the described block;
- init – initialized parameters;
- value – the value of the specified parameter;
- variable – type of variable;
- mark – the meaning of the sign;
- number – the value of the number;
- operator – the value of the operator;
- prefix – using the prefix;
- argument – the value of the argument.
- Conclusion
This article analyzes the existing implementations of serial code translators into parallel code, presents the architecture of a fundamentally new translator, and describes the syntax tree. An example of the formation of a syntactic tree is also demonstrated, the construction of which is provided by the performance of lexical, syntactic and semantic analyses. In the future, it is planned to expand the structural representation of the syntactic tree, to supplement the code conversion service with modules for converting serial code into parallel code using a neural network approach [11,12].
References
1. P. Czarnul, J. Proficz and K. Drypczewski, “Survey of methodologies, approaches, and challenges in parallel programming using high-performance computing systems,” Scientific Programming, vol. 2020, pp. 1058–9244, 2020.
2. D. B. Changdao, I. Firmansyah and Y. Yamaguchi, “FPGA-based computational fluid dynamics simulation architecture via high-level synthesis design method,” in Applied Reconfigurable Computing. Architectures, Tools, and Applications: 16th Int. Symp., ARC 2020, Toledo, Spain, Springer Nature. vol. 12083, pp. 232, 2020.
3. D. Wang and F. Yuan, “High-performance computing for earth system modeling,” High Performance Computing for Geospatial Applications, vol. 23, pp. 175–184, 2020.
4. M. U. Ashraf, F. A. Eassa, A. Ahmad and A. Algarni, “Empirical investigation: Performance and power-consumption based dual-level model for exascale computing systems,” IET Software, vol. 14, no. 4, pp. 319–327, 2020.
5. B. Brandon, “Message passing interface (mpi),” in Workshop: High Performance Computing on Stampede, Cornell University Center for Advanced Computing (CAC), vol. 262, 2015.
6. A. Podobas and S. Karlsson, “Towards unifying openmp under the task-parallel paradigm,” in Int. Workshop on OpenMP. Springer International Publishing, Springer International Publishing, Nara, Japan, vol. 9903, pp. 116–129, 2016.
7. M. U. Ashraf, F. Fouz and F. A. Eassa, “Empirical analysis of hpc using different programming models,” International Journal of Modern Education & Computer Science, vol. 8, no. 6, pp. 27–34, 2016.
8. J. A. Herdman, W. P. Gaudin, S. Smith, M. Boulton, D. A. Beckingsale et al., “Accelerating hydrocodes with openacc, opencl and cuda,” High Performance Computing, Networking, Storage and Analysis (SCC), vol. 66, pp. 465–471, 2012.
9. H. Jin, D. Jespersen, P. Mehrotra, R. Biswas, L. Huang et al., “High performance computing using mpi and openmp on multi-core parallel systems,” Parallel Computing, vol. 37, no. 9, pp. 562–575, 2011.
10. M. Marangoni and T. Wischgoll, “Togpu: Automatic source transformation from c++ to cuda using clang/llvm,” Electronic Imaging, vol. 1, pp. 1–9, 2016.
11. X. Xie, B. Chen, L. Zou, Y. Liu, W. Le et al., “Automatic loop summarization via path dependency analysis,” IEEE Transactions on Software Engineering, vol. 45, no. 6, pp. 537–557, 2017.
12. M. S. Ahmed, M. A. Belarbi, S. Mahmoudi, G. Belalem and P. Manneback, “Multimedia processing using deep learning technologies, high-performance computing cloud resources, and big data volumes,” Concurrency and Computation: Practice and Experience, vol. 32, no. 17, pp. 56–99, 2020
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The subject of the research is the development of a syntax tree for an automated translator of serial program code into parallel code for multicore processors. The research methodology is based on a theoretical approach using methods of analysis, modeling, algorithmization, schematization, generalization, comparison, synthesis. The relevance of the research is determined by the widespread use of parallel computing technologies, the need to develop appropriate software systems and computational methods, including the development of a syntax tree for an automated translator for multicore processors. The scientific novelty is associated with the translator architecture proposed by the author of a new translator for the translation of sequential code into parallel, the description of a syntactic tree, the construction of which is provided by the performance of lexical, syntactic and semantic analyses. The article is written in Russian literary language. The style of presentation is scientific. The structure of the manuscript includes the following sections: Introduction (increasing the number of multiprocessor complexes, solving computationally complex problems in an acceptable time, developing software modules using multithreaded programming, participation of an analyst, programmer, testing specialist, specialized Cilk language, synchronization point, divide and conquer style, or fork-join parallelism, specialized Java Fork Join libraries, the question of automated (or automatic) conversion of serial code into parallel, automated translator, dialogue with the programmer, optimization of the algorithm for the use of hardware resources and performance criteria, well-known software products Polaris, Cetus, Pluto, Polly, Par4All, CAPO, WPP, SUIF, VAST/PARALLEL, OSCAR, SAPPHIRE, comparative analysis using the example of Parawise, CAPO algorithm), Translator architecture (the decision to make a web application, microservice architecture of the translator, query processing service, tree building service, parallel program generation services, code conversion service, sequence diagram for creating parallel programs using a message broker), Building syntax tree (syntax tree formats, ANTLR4, Babel AST, proprietary format, lexical analysis of the input program, syntactic analysis, semantic analysis, conversion to intermediate code in JSON format, example of conversion to a syntactic tree, description of the fields used), Conclusion, Bibliography. The text is six figures. Figures 5 and 6 need to be mentioned in the preceding text. The content generally corresponds to the title. The author analyzes the known implementations of serial code translators into parallel, presents the original architecture of the translator, and describes the syntactic tree. The prospects of work related to the application of the neural network approach are determined. The bibliography includes 12 sources of foreign authors – chapters of monographs, scientific articles, materials of scientific events, etc. Bibliographic descriptions of some sources require adjustments in accordance with GOST and editorial requirements, for example: 1. Czarnul P. , Proficz J. , Drypczewski K. Survey of methodologies, approaches, and challenges in parallel programming using high-performance computing systems // Scientific Programming. 2020. Vol. 2020. P. 1058–9244. 2. Changdao D. B., Firmansyah I., Yamaguchi Y. FPGA-based computational fluid dynamics simulation architecture via high-level synthesis design method // Applied Reconfigurable Computing. Architectures, Tools, and Applications: 16th Int. Symp. ARC 2020. Toledo, Spain : Springer Nature, 2020. Vol. 12083. P. 232. 4. Ashraf M. U., Eassa F. A, Ahmad A., Algarni A. Empirical investigation: Performance and power-consumption based dual-level model for exascale computing systems // IET Software, 2020. Vol. 14. ą 4. P. 319–327. Attention is drawn to the lack of references to the work of domestic specialists. Appeal to opponents (P. Czarnul, J. Proficz, K. Drypczewski, D. B. Changdao, I. Firmansyah, Y. Yamaguchi, D. Wang, F. Yuan, M. U. Ashraf, F. A. Eassa, A. Ahmad, A. Algarni, B. Brandon, A. Podobas, S. Karlsson, M. U. Ashraf, F. Fouz, F. A. Eassa, J. A. Herdman, W. P. Gaudin, S. Smith, M. Boulton, D. A. Beckingsale, H. Jin, D. Jespersen, P. Mehrotra, R. Biswas, L. Huang, M. Marangoni, T. Wischgoll, X. Xie, B. Chen, L. Zou, Y. Liu, W. Le, M. S. Ahmed, M. A. Belarbi, S. Mahmoudi, G. Belalem, P. Manneback, etc.) takes place. In general, the material is of interest to the readership and, after revision, can be published in the journal "Software Systems and Computational Methods".
|










