|
DOI: 10.25136/2644-5522.2020.1.32143
Received:
08-02-2020
Published:
03-07-2020
Abstract:
The subject of the research is the possibility of using XPath-like micro-languages of programming in the generation systems of programs of the PGEN ++ class for the selection and completion of XML-models describing the plan for solving the original problem, according to which the solver program is generated. It is supposed to build such models according to the description of the problem in natural language, thus, we are talking about elements of artificial intelligence technologies. XPath-like language works in the layer of regular-logical expressions (highlighting elements of the primary XML document), performing primary processing of the data obtained in the layer of grammatical parsing of the source text. In addition, XPath-like elements are used to render the final XML models. The standard natural language parsing libraries are used. Non-standard XPath query language extensions are used. For the first time, the idea of expanding the XPath query language to the level of an algorithmic language by introducing the minimum required number of syntactic elements is proposed. It is also proposed to use syntactic elements with an XPath-like structure as both generating and controlling weak constraints of the process of direct inference of final semantic XML models.
Keywords:
artifical intelligence, program generation, algorithmic XPath, weak restrictions, model completion, algorithmic completness, natural-language processing, sense model, direct inference, link-grammar parsing
Îäíîé čç âŕćíűő çŕäŕ÷ â îáëŕńňč čńęóńńňâĺííîăî číňĺëëĺęňŕ ˙âë˙ĺňń˙, â ÷ŕńňíîńňč, çŕäŕ÷ŕ ăĺíĺđŕöčč đĺřŕţůĺé íĺęîňîđóţ ďđîáëĺěó ďđîăđŕěěű ďî ĺńňĺńňâĺííî-˙çűęîâîěó îďčńŕíčţ ýňîé ďđîáëĺěű. Äŕííŕ˙ çŕäŕ÷ŕ, ęîňîđóţ ďđč ńîâđĺěĺííîě óđîâíĺ đŕçâčňč˙ ňĺőíîëîăčé čńęóńńňâĺííîăî číňĺëëĺęňŕ âđ˙ä ëč âîçěîćíî đĺřčňü óíčâĺđńŕëüíî č â ďîëíîě îáúĺěĺ, ňĺě íĺ ěĺíĺĺ ěîćĺň ýôôĺęňčâíî đĺřŕňüń˙ ńčńňĺěŕěč ďîđîćäĺíč˙ ďđîăđŕěě â öĺëîě đ˙äĺ äîńňŕňî÷íî ďđîđŕáîňŕííűő č ôîđěŕëčçîâŕííűő îáëŕńňĺé (ěŕňĺěŕňč÷ĺńęčĺ çŕäŕ÷č, çŕäŕ÷č ďđîĺęňčđîâŕíč˙ ńňŕíäŕđňčçîâŕííűő ňĺőíč÷ĺńęčő îáúĺęňîâ, đŕçëč÷íűĺ ňčďîâűĺ çŕäŕ÷č ďđîăđŕěěčđîâŕíč˙ [â ÷ŕńňíîńňč, ăĺíĺđŕöč˙ číňĺđôĺéńîâ, ăĺíĺđŕöč˙ Web-ęîíňĺíňŕ, ăĺíĺđŕöč˙ ďîäńčńňĺě äë˙ đŕáîňű ń áŕçŕěč äŕííűő č ěíîăčĺ äđóăčĺ řŕáëîííî đĺřŕĺěűĺ çŕäŕ÷č]). Ďîýňîěó, äŕííŕ˙ çŕäŕ÷ŕ číňĺđĺńíŕ íĺ ňîëüęî ňĺîđĺňč÷ĺńęč, íî č ďđŕęňč÷ĺńęč, č, íĺńîěíĺííî, ŕęňóŕëüíŕ.
Ńóůĺńňâóĺň äâŕ îńíîâíűő íŕďđŕâëĺíč˙ đĺřĺíč˙ ďîńňŕâëĺííîé çŕäŕ÷č: ŕ) ďđ˙ěŕ˙ ňđŕíńôîđěŕöč˙ ďîńňŕíîâî÷íîăî ňĺęńňŕ íŕ ĺńňĺńňâĺííîě ˙çűęĺ â ňĺęńň ďđîăđŕěěű [1, 2] č á) ěíîăîńňŕäčéíŕ˙ ňđŕíńôîđěŕöč˙ ĺńňĺńňâĺííî-˙çűęîâîé ďîńňŕíîâęč â ďđîăđŕěěó (îá˙çŕňĺëüíűě ęîěďîíĺíňîě ňŕęîé ňđŕíńôîđěŕöčč ˙âë˙ĺňń˙ âűđŕáîňęŕ íĺęîňîđîé ńěűńëîâîé ěîäĺëč (íŕďđčěĺđ, ďëŕíŕ đĺřĺíč˙ çŕäŕ÷č) [3, 4, 5]).
Ďĺđâîĺ íŕďđŕâëĺíčĺ ěîćĺň čńďîëüçîâŕňü ďđîäóęöčîííűĺ ďđŕâčëŕ â ńî÷ĺňŕíčč ń íĺéđîńĺň˙ěč, îďđĺäĺë˙ţůčěč ńđŕâíčňĺëüíűĺ âĺđî˙ňíîńňč ďđčěĺíĺíč˙ ňîăî čëč číîăî ďđŕâčëŕ (ęŕę ýňî ńäĺëŕíî â đŕáîňĺ [1]), čëč ďđčáĺăŕňü ę ďîěîůč ňĺőíîëîăčč Statistical Machine Translation (SMT), ęîňîđŕ˙ îďđĺäĺë˙ĺň ńňŕňčńňč÷ĺńęč ëó÷řčĺ âŕđčŕíňű ďđ˙ěîé ňđŕíńë˙öčč îňäĺëüíűő ôđŕăěĺíňîâ âőîäíîé ďîńňŕíîâęč â ôđŕăěĺíňű âűőîäíîé ďîńňŕíîâęč, îáúĺäčí˙ĺň čő č ďđîâĺđ˙ĺň đĺçóëüňŕň ďî íĺęîňîđîé ˙çűęîâîé ěîäĺëč [2]. Ďđč âńĺé číňĺđĺńíîńňč äŕííîăî íŕďđŕâëĺíč˙ íĺëüç˙ íĺ ďđčçíŕňü, ÷ňî îíî áîëĺĺ ďĺđńďĺęňčâíî äë˙ đĺřĺíč˙ äîńňŕňî÷íî ëîęŕëüíűő çŕäŕ÷, ňŕęčő ęŕę ŕâňîęîěěĺíňčđîâŕíčĺ ďđîăđŕěěíîăî ęîäŕ čëč ěŕřčííűé ďĺđĺâîä, âűďîëí˙ĺěűé ďî îňäĺëüíűě ďđĺäëîćĺíč˙ě. Çŕäŕ÷ŕ ćĺ ăĺíĺđŕöčč ďđîăđŕěěű ěîćĺň ňđĺáîâŕňü ęîěďëĺęńíîăî ŕíŕëčçŕ ńěűńëŕ čńőîäíîăî ňĺęńňŕ â öĺëîě.
Ďîýňîěó, áîëĺĺ ďđîäóęňčâíűě ďđĺäńňŕâë˙ĺňń˙ âňîđîĺ íŕďđŕâëĺíčĺ.  ĺăî đŕěęŕő âîçěîćíű đŕçëč÷íűĺ ďîäőîäű ę ďîńňđîĺíčţ ńěűńëîâîé ěîäĺëč. Íŕďđčěĺđ, â ńčńňĺěĺ IPGS [3] čńďîëüçóţňń˙ ěíîăîëĺíňî÷íűĺ ěŕřčíű Ňüţđčíăŕ â ńî÷ĺňŕíčč ń ýëĺěĺíňŕěč ňĺîđčč ôîđěŕëüíűő ăđŕěěŕňčę. Äŕííűé ďîäőîä âđ˙ä ëč ďđîńň â ďđčěĺíĺíčč, áîëĺĺ ďĺđńďĺęňčâíűě ďđĺäńňŕâë˙ĺňń˙ ďîäőîä, ďđč ęîňîđîě čńďîëüçóţňń˙ (â ňîé čëč číîé ôîđěĺ) őîđîřî čçâĺńňíűĺ ńőĺěű îďđĺäĺëĺíč˙ ăđŕěěŕňč÷ĺńęčő ńâ˙çĺé ěĺćäó îňäĺëüíűěč ńëîâŕěč [6], äŕćĺ íŕ îńíîâŕíčč ďĺđâč÷íîăî ŕíŕëčçŕ ęîňîđűő óćĺ ěîćíî äĺëŕňü íĺęîňîđűĺ âűâîäű î ńîäĺđćŕíčč ďîńňŕâëĺííîé çŕäŕ÷č. Ňŕęîé ďîäőîä óńďĺříî ďđĺäńňŕâëĺí, íŕďđčěĺđ, â đŕáîňŕő [4, 5]. Îäíŕęî íĺëüç˙ íĺ îňěĺňčňü îáůčé íĺäîńňŕňîę ýňčő đŕáîň – ęđŕéíţţ ďđîńňîňó ďîëó÷ŕĺěîé ńěűńëîâîé ěîäĺëč č ěĺőŕíčçěŕ, đĺŕëčçóţůĺăî ăĺíĺđŕöčţ ęîäŕ (čńďîëüçóţňń˙ ńďĺöčŕëüíűĺ ňŕáëčöű ňđŕíńë˙öčč). Âűçűâŕĺň îďđĺäĺëĺííîĺ ńîěíĺíčĺ ďđčăîäíîńňü ďîäîáíîé ńőĺěű äë˙ ńóůĺńňâĺííî áîëĺĺ ńëîćíűő ńëó÷ŕĺâ (íĺćĺëč đŕçîáđŕííűĺ â óďîě˙íóňűő đŕáîňŕő), îńîáĺííî ňđĺáóţůčő äîďîëíĺíč˙ âűäĺëĺííîé ńěűńëîâîé ěîäĺëč (ęîňîđŕ˙ ěîćĺň áűňü ďđĺäńňŕâëĺíŕ â ęđŕéíĺ íĺďîëíîě, âîçěîćíî, ÷čńňî äĺęëŕđŕňčâíîě âčäĺ) äî ďîëíîăî ďëŕíŕ đĺřĺíč˙ çŕäŕ÷č.
Ďđĺäńňŕâë˙ĺňń˙ öĺëĺńîîáđŕçíűě ďîńňđîĺíčĺ ńěűńëîâîé ěîäĺëč çŕ äâŕ ýňŕďŕ. Íŕ ďĺđâîě ýňŕďĺ íĺîáőîäčěî ďđîâĺńňč ëĺęńčęî-ńčíňŕęńč÷ĺńęčé đŕçáîđ čńőîäíîăî ňĺęńňŕ íŕ ĺńňĺńňâĺííîě ˙çűęĺ ń đŕçáčâęîé ĺăî íŕ ďđĺäëîćĺíč˙, ń âű˙âëĺíčĺě îňäĺëüíűő ýëĺěĺíňîâ ďđĺäëîćĺíčé č ŕíŕëčçîě ăđŕěěŕňč÷ĺńęčő ńâ˙çĺé ěĺćäó ýňčěč ýëĺěĺíňŕěč.  đĺçóëüňŕňĺ ďîëó÷ŕĺě ďĺđâč÷íóţ ôŕęňîëîăč÷ĺńęóţ ěîäĺëü ňĺęńňŕ, âęëţ÷ŕţůóţ íŕáîđ âűńęŕçűâŕíčé, ęŕćäîĺ čç ęîňîđűő ěîćĺň áűňü îďčńŕíî îáúĺęňîě íĺęîňîđîăî ęëŕńńŕ çŕäŕííîé ďđĺäěĺňíîé îáëŕńňč (ńőîćčé ďîäőîä ďđčěĺíĺí â [5]). Ęŕćäűé ęëŕńń ďđĺäńňŕâë˙ĺň ëčáî íĺęîňîđóţ ńóůíîńňü, ëčáî äĺéńňâčĺ, ëčáî îňíîřĺíčĺ, ŕ ďîë˙ ńîîňâĺňńňâóţůĺăî îáúĺęňŕ ňŕęîăî ęëŕńńŕ ńîäĺđćčň, ńîîňâĺňńňâĺííî, ŕňđčáóňű ńóůíîńňč, îáúĺęň/ńóáúĺęň äĺéńňâč˙, ďŕđŕěĺňđű îňíîřĺíč˙.
Íŕ âňîđîě ýňŕďĺ ďîńňđîĺíč˙ ńěűńëîâîé ěîäĺëč âű˙âëĺííűé íŕáîđ ďĺđâč÷íűő îáúĺęňîâ ŕíŕëčçčđóĺňń˙ (óćĺ íŕ óđîâíĺ îňíîřĺíčé ěĺćäó đŕçëč÷íűěč îáúĺęňŕěč) č äîńňđŕčâŕĺňń˙ äî ďîëíîé ěîäĺëč, ńîäĺđćŕůĺé óćĺ âńĺ íĺîáőîäčěóţ äë˙ đĺřĺíč˙ ďîńňŕâëĺííîé çŕäŕ÷č číôîđěŕöčţ. Äŕííűé ďđîöĺńń äîńňŕňî÷íî íĺňđčâčŕëĺí ŕëăîđčňěč÷ĺńęč, ďîýňîěó ĺăî öĺëĺńîîáđŕçíî đĺřŕňü â íĺęîňîđîé ôîđěŕëüíî-ëîăč÷ĺńęîé ďîńňŕíîâęĺ. Çäĺńü, âîîáůĺ ăîâîđ˙, âîçěîćíű äâŕ îńíîâíűő ďîäőîäŕ – ďđ˙ěîé č îáđŕňíűé ëîăč÷ĺńęčé âűâîä. Îáđŕňíűé âűâîä öĺëĺńîîáđŕçíî čńďîëüçîâŕňü â ńëó÷ŕ˙ő, ęîăäŕ ÷ĺňęî ˙ńíŕ ńňđóęňóđŕ öĺëĺâîăî óňâĺđćäĺíč˙.  íŕřĺě ńëó÷ŕĺ ýňî, ôŕęňč÷ĺńęč, îçíŕ÷ŕĺň, ÷ňî äîëćíű áűňü çŕđŕíĺĺ ˙ńíű ńňđóęňóđŕ č ńîńňŕâ ęîíĺ÷íîé ńěűńëîâîé ěîäĺëč. Íŕ ďđŕęňčęĺ ýňî íĺ ňŕę. Ďîýňîěó áîëĺĺ öĺëĺńîîáđŕçíî ďđčěĺíĺíčĺ ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ, äë˙ ęîňîđîăî çŕäŕĺňń˙ íĺ öĺëĺâîĺ óňâĺđćäĺíčĺ, ŕ íĺęîňîđűĺ íŕáîđű îăđŕíč÷ĺíčé ďđîöĺńńŕ ďîńňđîĺíč˙ č íŕáîđű ňĺńňîâ, ÷ĺđĺç ęîňîđűĺ äîëćíŕ óńďĺříî ďđîőîäčňü ďđîăđŕěěŕ, ńăĺíĺđčđîâŕííŕ˙ ďî î÷ĺđĺäíîěó (ôîđěŕëüíî ęîđđĺęňíîěó) âŕđčŕíňó ďëŕíŕ đĺřĺíč˙ çŕäŕ÷č.
Çŕěĺňčâ, ÷ňî ýôôĺęňčâíîĺ ďđîăđŕěěčđîâŕíčĺ ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ ˙âë˙ĺňń˙ äîńňŕňî÷íî íĺňđčâčŕëüíîé çŕäŕ÷ĺé äŕćĺ äë˙ ďđîăđŕěěčńňŕ, ŕ ďîëüçîâŕňĺë˙ěč ńčńňĺěű ďîđîćäĺíč˙ ďđîăđŕěě ďđĺčěóůĺńňâĺííî ˙âë˙ţňń˙ íĺďđîăđŕěěčđóţůčĺ ńďĺöčŕëčńňű ďî çíŕíč˙ě â îďđĺäĺëĺííűő ďđĺäěĺňíűő îáëŕńň˙ő, öĺëĺńîîáđŕçíî ěŕęńčěŕëüíî óďđîńňčňü ęŕę ôîđěó ďđĺäńňŕâëĺíč˙ ńěűńëîâîé ěîäĺëč, ňŕę č ďđŕâčëŕ ĺĺ ýëĺěĺíňŕđíîăî ŕíŕëčçŕ č ëîăč÷ĺńęîăî äîńňđŕčâŕíč˙.
Ňŕęîé ôîđěîé ěîćĺň áűňü XML-äîęóěĺíň, íŕáîđ ňýăîâ ęîňîđîăî ńďîńîáĺí ńîäĺđćŕňü îďčńŕíč˙ íĺ ňîëüęî îáúĺęňîâ, âőîä˙ůčő â ďëŕí đĺřĺíč˙ çŕäŕ÷č, íî č îňíîřĺíčé ěĺćäó íčěč.  ńâ˙çč ń ýňčě ëîăč÷íî âűáđŕňü â ęŕ÷ĺńňâĺ áŕçîâîăî ńđĺäńňâŕ ŕíŕëčçŕ č äîńňđŕčâŕíč˙ äîęóěĺíňŕ ęŕęîé-ëčáî čç ńňŕíäŕđňíűő ôîđěŕëüíűő ˙çűęîâ îáđŕáîňęč XML-äîęóěĺíňîâ.  ÷ŕńňíîńňč, äîńňŕňî÷íî číňĺđĺńíűě ďđĺäńňŕâë˙ĺňń˙ âűáîđ ˙çűęŕ çŕďđîńîâ XPath, ďđč÷ĺě ńóůĺńňâĺííűé (íĺ ňîëüęî ňĺîđĺňč÷ĺńęčé, íî č ďđŕęňč÷ĺńęčé) číňĺđĺń ďđĺäńňŕâë˙ţň ĺăî ěîäčôčęŕöčč, ďîçâîë˙ţůčĺ ďđčěĺíčňü îńíîâŕííűé íŕ XPath ńčíňŕęńčń äë˙ ęîíńňđóčđîâŕíč˙ č îďčńŕíč˙ íĺáîëüřčő ďđîńňűő ŕëăîđčňěîâ, íîń˙ůčő âńďîěîăŕňĺëüíűé őŕđŕęňĺđ.
Čňŕę, öĺëüţ äŕííîé đŕáîňű ˙âë˙ĺňń˙ ďîâűřĺíčĺ ôóíęöčîíŕëüíîńňč ńőĺě ďîđîćäĺíč˙ ďđîăđŕěě ďî ĺńňĺńňâĺííî-˙çűęîâîé ďîńňŕíîâęĺ çŕäŕ÷č. Äë˙ äîńňčćĺíč˙ äŕííîé öĺëč ďîńňŕâčě ńëĺäóţůčĺ çŕäŕ÷č: ŕ) ďđĺäëîćčňü (íŕ áŕçĺ XPath) ďđîńňűĺ ˙çűęîâűĺ ńđĺäńňâŕ îáđŕáîňęč đĺçóëüňŕňîâ ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ ďđč ďîńňđîĺíčč ďĺđâč÷íîé ńěűńëîâîé ěîäĺëč; á) ďđĺäëîćčňü ŕäĺęâŕňíűĺ ˙çűęîâűĺ ńđĺäńňâŕ (ňŕęćĺ íŕ áŕçĺ XPath) äë˙ ŕíŕëčçŕ ďĺđâč÷íîé ńěűńëîâîé ěîäĺëč č ĺĺ äîńňđŕčâŕíč˙ äî ďîëíîé ěîäĺëč; â) đĺŕëčçîâŕňü ďđĺäëîćĺííűĺ ńőĺěű č ďîäőîäű â ńčńňĺěĺ ďîđîćäĺíč˙ ďđîăđŕěě PGEN++ [7, 8], ęîňîđŕ˙ îáĺńďĺ÷čâŕĺň óńďĺříóţ ăĺíĺđŕöčţ ďđîăđŕěě â ÷ĺňęî ôîđěŕëčçîâŕííűő ďđĺäěĺňíűő îáëŕńň˙ő, äë˙ ęîňîđűő âîçěîćíŕ đŕçđŕáîňęŕ ŕäĺęâŕňíűő ďîđîćäŕţůčő ęëŕńńîâ.
Ďđčěĺíĺíčĺ XPath-ďîäîáíîăî ˙çűęŕ ďđč ďîńňđîĺíčč ďĺđâč÷íîé ńěűńëîâîé ěîäĺëč
Ęŕę óćĺ áűëî îňěĺ÷ĺíî âűřĺ, ďîńňđîĺíčĺ ďĺđâč÷íîé ńěűńëîâîé ěîäĺëč â ńčńňĺěĺ PGEN++ âęëţ÷ŕĺň ëĺęńčęî-ńčíňŕęńč÷ĺńęčé đŕçáîđ čńőîäíîăî ňĺęńňŕ ń đŕçáčâęîé ĺăî íŕ ďđĺäëîćĺíč˙, ń âű˙âëĺíčĺě îňäĺëüíűő ýëĺěĺíňîâ ďđĺäëîćĺíčé č ŕíŕëčçîě ăđŕěěŕňč÷ĺńęčő ńâ˙çĺé ěĺćäó ýňčěč ýëĺěĺíňŕěč. Äŕííűĺ îďĺđŕöčč âűďîëí˙ţňń˙ ńďĺöčŕëüíűěč ęëŕńńŕěč (čç îďčńŕíč˙ ďđĺäěĺňíîé îáëŕńňč), íŕăđóćĺííűěč đŕńďîçíŕţůčěč ěĺňîäŕěč, ęŕćäűé čç ęîňîđűő ńîäĺđćčň řŕáëîí đŕçáîđŕ, ďđĺäńňŕâë˙ţůčé ńîáîé ăđóďďó đĺăóë˙đíî-ëîăč÷ĺńęčő âűđŕćĺíčé â ńî÷ĺňŕíčč ń íŕáîđîě óęŕçŕíčé ďî čçâëĺ÷ĺíčţ číôîđěŕöčč čç đĺçóëüňŕňîâ đŕçáîđŕ č ďîěĺůĺíčţ čő â ďîë˙ îáúĺęňîâ, ôîđěčđóţůčő ďĺđâč÷íóţ XML-ěîäĺëü.
Đĺăóë˙đíî-ëîăč÷ĺńęčĺ âűđŕćĺíč˙ (â áŕçîâîé âĺđńčč äîńňŕňî÷íî ďîäđîáíî îďčńŕíű â đŕáîňĺ [8]) ďđĺäńňŕâë˙ţň ńîáîé đŕńřčđĺíčĺ ńňŕíäŕđňíűő đĺăóë˙đíűő âűđŕćĺíčé [9], âęëţ÷ŕţůĺĺ âîçěîćíîńňü čńďîëíĺíč˙ öĺďî÷ĺę ńďĺöčŕëüíűő ěčęđîďđĺäčęŕňîâ, âűďîëí˙ţůčő âńďîěîăŕňĺëüíóţ îáđŕáîňęó đŕńďîçíŕííűő ôđŕăěĺíňîâ – ďđîâĺđęó ďî ďđîńňĺéřčě CSV-ňŕáëčöŕě, ěîäčôčęŕöčč ňŕęčő ňŕáëčö, đŕáîňó ń íĺéđîííűěč ńĺň˙ěč ďđ˙ěîăî đŕńďđîńňđŕíĺíč˙, ŕ ňŕęćĺ đŕçëč÷íűĺ ńëîćíűĺ ŕëăîđčňěč÷ĺńęčĺ ďđîâĺđęč, â ÷čńëî ęîňîđűő âőîäčň ăđŕěěŕňč÷ĺńęčé ŕíŕëčç ôđŕăěĺíňîâ ďđĺäëîćĺíčé íŕ ĺńňĺńňâĺííîě ˙çűęĺ (íŕ íčćíĺě óđîâíĺ ňŕęčő ďđîâĺđîę čńďîëüçóĺňń˙ áčáëčîňĺęŕ Link Grammar 5.3.0 [10]). Âűőîäíŕ˙ číôîđěŕöč˙ áčáëčîňĺęč Link Grammar (íŕáîđ âű˙âëĺííűő ăđŕěěŕňč÷ĺńęčő ńâ˙çĺé ěĺćäó ńëîâŕěč) ďđĺäńňŕâë˙ĺňń˙ (äë˙ îáĺńďĺ÷ĺíč˙ ĺäčíîîáđŕçíîăî ôîđěŕňŕ äŕííűő â ńčńňĺěĺ) â âčäĺ âčđňóŕëüíîăî XML-äîęóěĺíňŕ, â ńâ˙çč ń ÷ĺě, â íŕáîđ ěčęđîďđĺäčęŕňîâ đĺăóë˙đíî-ëîăč÷ĺńęčő âűđŕćĺíčé ďîňđĺáîâŕëîńü ââĺńňč ńďĺöčŕëüíűĺ ńđĺäńňâŕ äë˙ đŕáîňű ń ňŕęčěč XML-äîęóěĺíňŕěč.  ńîîňâĺňńňâčč ń îáůĺé ęîíöĺďöčĺé äŕííîé đŕáîňű áűëî ďđčí˙ňî đĺřĺíčĺ čńďîëüçîâŕňü â ęŕ÷ĺńňâĺ ňŕęčő ńđĺäńňâ XPath-ďîäîáíűé çŕďđîńî-ŕëăîđčňěč÷ĺńęčé ˙çűę, äîďîëíčâ ńňŕíäŕđňíűé XPath íĺńęîëüęčěč ęîíńňđóęöč˙ěč.
Â-öĺëîě, ńňŕíäŕđňíűé XPath óćĺ čěĺĺň äîńňóďíűĺ äë˙ ÷ňĺíč˙ ďĺđĺěĺííűĺ (çŕďčńűâŕĺěűĺ â ôîđěŕňĺ $ČĚß) č îáëŕäŕĺň ýëĺěĺíňŕđíűěč âîçěîćíîńň˙ěč ďîńëĺäîâŕňĺëüíîăî č âĺňâ˙ůĺăîń˙ čńďîëíĺíč˙ ńĺđčé ëîăč÷ĺńęčő ôóíęöčé (ďđč óńëîâčč, ÷ňî čńďîëüçóĺňń˙ ńňŕíäŕđňíŕ˙ ęîíöĺďöč˙ ńîęđŕůĺííîăî čńďîëíĺíč˙ ëîăč÷ĺńęčő âűđŕćĺíčé).  ńŕěîě äĺëĺ, XPath-âűđŕćĺíčĺ âčäŕ
A(…) and B(…) and C(…)
ěîćĺň ňđŕęňîâŕňüń˙ ęŕę ëčíĺéíűé ôđŕăěĺíň ďđîăđŕěěű, ďîäđŕçóěĺâŕţůčé ďîńëĺäîâŕňĺëüíűé âűçîâ ôóíęöčé A(…), B(…) č C(…), ďđč óńëîâčč, ÷ňî äŕííűĺ ôóíęöčč âîçâđŕůŕţň čńňčííîĺ ëîăč÷ĺńęîĺ çíŕ÷ĺíčĺ. Ŕíŕëîăč÷íî, âűđŕćĺíčĺ
D(…) and E(…) or F(…)
ěîćĺň đŕńńěŕňđčâŕňüń˙ ęŕę óńëîâíűé îďĺđŕňîđ, ęîňîđűé čńďîëí˙ĺň ëčáî ôóíęöčţ E(…), ĺńëč đĺçóëüňŕň D(…) čńňčíĺí, ëčáî ôóíęöčţ F(…), ĺńëč đĺçóëüňŕň D(…) ëîćĺí.
Ňŕęčě îáđŕçîě, ÷ňîáű ďîęđűňü áŕçîâűĺ ďîňđĺáíîńňč ďđîăđŕěěčđîâŕíč˙, íĺîáőîäčěî ââĺńňč âîçěîćíîńňü ďđîăđŕěěíîăî îďđĺäĺëĺíč˙ íîâűő ôóíęöčé XPath (ĺńëč ďđč ýňîě đŕçđĺřčňü đĺęóđńčţ, ňî ń ďîěîůüţ ôóíęöčé ěîćíî đĺŕëčçîâŕňü ĺůĺ č öčęëű) č ââĺńňč, ęŕę ěčíčěóě, îäíó íîâóţ ńňŕíäŕđňíóţ ôóíęöčţ (đĺçóëüňŕň čńďîëíĺíč˙ ęîňîđîé âńĺăäŕ čńňčíĺí)
«set» «(» «$» čě˙_ďĺđĺěĺííîé «,» âűđŕćĺíčĺ «)»
ęîňîđŕ˙ ďîçâîëčň ďđčńâŕčâŕňü çíŕ÷ĺíčĺ âűđŕćĺíč˙ ďĺđĺěĺííîé.
Ďđĺäëŕăŕĺňń˙ ńëĺäóţůčé ńčíňŕęńčń ďđîăđŕěěíî îďđĺäĺë˙ĺěîé ôóíęöčč:
ôóíęöč˙ = «*» čě˙_ôóíęöčč «(» [ńďčńîę_ďŕđŕěĺňđîâ] «)» XPath-âűđŕćĺíčĺ «.»
čě˙_ôóíęöčč = čäĺíňčôčęŕňîđ
ńďčńîę_ďŕđŕěĺňđîâ = ďŕđŕěĺňđ {«,» ďŕđŕěĺňđ}
ďŕđŕěĺňđ = ďŕđŕěĺňđ_ďî_ńńűëęĺ | ďŕđŕěĺňđ_ďî_çíŕ÷ĺíčţ
ďŕđŕěĺňđ_ďî_ńńűëęĺ = «&» «$» čäĺíňčôčęŕňîđ
ďŕđŕěĺňđ_ďî_çíŕ÷ĺíčţ = ďŕđŕěĺňđ_óęŕçŕňĺëü | ďŕđŕěĺňđ_íĺ_óęŕçŕňĺëü
ďŕđŕěĺňđ_óęŕçŕňĺëü = «$» «#» {«#»} [čäĺíňčôčęŕňîđ]
ďŕđŕěĺňđ_íĺ_óęŕçŕňĺëü = «$» čäĺíňčôčęŕňîđ
ăäĺ XPath-âűđŕćĺíčĺ ˙âë˙ĺňń˙ ňĺëîě ôóíęöčč, ďđč÷ĺě ĺăî çíŕ÷ĺíčĺ îďđĺäĺë˙ĺň đĺçóëüňŕň čńďîëíĺíč˙ ôóíęöčč. Ďŕđŕěĺňđű ěîăóň ďĺđĺäŕâŕňüń˙ ęŕę ďî ńńűëęĺ, ňŕę č ďî çíŕ÷ĺíčţ, čő čěĺíŕ âńĺăäŕ ďđĺôčęńóţňń˙ ńčěâîëîě «$». Čěĺíŕ ÷čńëîâűő, ńňđîęîâűő č ëîăč÷ĺńęčő ďŕđŕěĺňđîâ ěîăóň áűňü ďđîčçâîëüíűěč čäĺíňčôčęŕňîđŕěč, čěĺíŕ ďŕđŕěĺňđîâ-óęŕçŕňĺëĺé íŕ îňäĺëüíűĺ ôđŕăěĺíňű XML-äîęóěĺíňŕ äîďîëíčňĺëüíî ďđĺôčęńóţňń˙ îäíčě čëč íĺńęîëüęčěč ńčěâîëŕěč «#» (ďđč ýňîě äë˙ ďîëó÷ĺíč˙ ýëĺěĺíňŕ ďî ňŕęîěó óęŕçŕňĺëţ â ňĺëĺ ôóíęöčč čńďîëüçóĺňń˙ ĺăî čě˙ ń ďđĺôčęńŕěč «#», íî áĺç íŕ÷ŕëüíîăî çíŕęŕ «$»). Âűçîâ ďđîăđŕěěíî îďđĺäĺë˙ĺěîé ôóíęöčč îôîđěë˙ĺňń˙ ňŕęčě ćĺ îáđŕçîě, ęŕę č âűçîâ ëţáîé ńňŕíäŕđňíîé XPath-ôóíęöčč.
Ďđčâĺäĺě äâŕ ďđčěĺđŕ ďđîăđŕěěíî îďđĺäĺë˙ĺěîé ôóíęöčč.
Đĺęóđńčâíŕ˙ ôóíęöč˙ loop($I, $max, $body) čńďîëí˙ĺň â öčęëĺ XPath-âűđŕćĺíčĺ, çŕďčńŕííîĺ â ńňđîęîâîě ďŕđŕěĺňđĺ $body, öčęë âűďîëí˙ĺňń˙ ďî ďĺđĺěĺííîé-ń÷ĺň÷čęó $I, îň ĺĺ ďĺđĺäŕííîăî íŕ÷ŕëüíîăî çíŕ÷ĺíč˙ äî çíŕ÷ĺíč˙ $max âęëţ÷čňĺëüíî.
* loop($I,$max,$body) ($I <= $max and set($I, $I+1) and eval($body) and loop($I,$max,$body)) or true().
Çäĺńü ôčăóđčđóĺň ĺůĺ îäíŕ íîâŕ˙ ńňŕíäŕđňíŕ˙ ôóíęöč˙:
eval «(» ńňđîęîâîĺ_âűđŕćĺíčĺ «)»
ęîňîđŕ˙ čńďîëí˙ĺň ďĺđĺäŕííîĺ â íĺĺ ńňđîęîâîĺ âűđŕćĺíčĺ, číňĺđďđĺňčđó˙ ĺăî ęŕę XPath-âűđŕćĺíčĺ. Âű÷čńëĺííîĺ çíŕ÷ĺíčĺ ýňîăî âűđŕćĺíč˙ ˙âë˙ĺňń˙ đĺçóëüňŕňîě ôóíęöčč eval.
Đĺęóđńčâíŕ˙ ôóíęöč˙ depth(&$OUT1) ďîěĺůŕĺň â ńâîé ďŕđŕěĺňđ $OUT1 çíŕ÷ĺíčĺ ěŕęńčěŕëüíîé ăëóáčíű ďîääĺđĺâŕ XML-ňýăîâ, íŕ÷číŕ˙ ń ňî÷ęč äîęóěĺíňŕ, â ęîňîđîé áűëŕ âűçâŕíŕ äŕííŕ˙ ôóíęöč˙:
* depth(&$OUT1) set($OUT1,0) and (self::*[set($OUT1,1) and *[depth($OUT0) and set($OUT1,max($OUT0+1,$OUT1))]] or true()).
Ńëĺäóĺň çŕěĺňčňü, ÷ňî, äë˙ ďîëíîöĺííîńňč, ňŕęîěó ěčęđî˙çűęó ďđîăđŕěěčđîâŕíč˙ íĺîáőîäčěŕ ňŕęćĺ ďîääĺđćęŕ äčíŕěč÷ĺńęčő ńňđóęňóđ äŕííűő (ęŕę ěčíčěóě čő ńîçäŕíč˙ č óäŕëĺíč˙). Ďîýňîěó öĺëĺńîîáđŕçĺí ââîä ĺůĺ ňđĺő íîâűő ôóíęöčé:
«create» «(» XPath-çŕďđîń «)»
ęîňîđŕ˙ ńîçäŕĺň íîâűĺ ýëĺěĺíňű XML-äîęóěĺíňŕ ďóňĺě ďđčěĺíĺíč˙ XPath-çŕďđîńŕ â ęîíńňđóčđóţůĺě ńěűńëĺ [11],
«delete» «(» XPath-çŕďđîń «)»
ęîňîđŕ˙ óäŕë˙ĺň ýëĺěĺíňű XML-äîęóěĺíňŕ, ęîňîđűĺ âîçâđŕůŕĺň XPath-çŕďđîń,
«transaction» «(» âűđŕćĺíčĺ «)»
ęîňîđŕ˙ âűďîëí˙ĺň âűđŕćĺíčĺ (ńîäĺđćŕůĺĺ create/delete-óňâĺđćäĺíč˙) â ĺäčíîě, ŕňîěŕđíî ďđčíčěŕĺěîě čëč îňěĺí˙ĺěîě áëîęĺ. Ĺńëč âűđŕćĺíčĺ čńňčííî, ňî ňđŕíçŕęöč˙ ďđčíčěŕĺňń˙, číŕ÷ĺ – îňěĺí˙ĺňń˙.
 ęŕ÷ĺńňâĺ ďđčěĺđŕ ďđčâĺäĺě íŕáîđ ôóíęöčé, ęîňîđűĺ ďîçâîë˙ţň ńîçäŕňü â XML-äîęóěĺíňĺ ńďčńîę ďóňĺě ęîíęŕňĺíŕöčč äâóő óćĺ ńóůĺńňâóţůčő ńďčńęîâ (ńďčńîę ďđĺäńňŕâë˙ĺň ńîáîé öĺďî÷ęó âëîćĺííűő ňýăîâ list ń ŕňđčáóňŕěč data, â ęîňîđűő őđŕí˙ňń˙ çíŕ÷ĺíč˙ ńîîňâĺňńňâóţůčő ýëĺěĺíňîâ ńďčńęŕ):
*concat_list($#,$##) add_list(#/self::*) and add_list(##/self::*).
*add_list($#) count(list) = 0 and copy_list(#/self::*) or list[add_list(#/self::*)] or true().
*copy_list($#) count(#/list) = 0 or create(list[@data = #/list/@data]) and (list[copy_list(#/list)] or true()).
Âűçîâ ôóíęöčč ęîíęŕňĺíŕöčč ďđč ýňîě ěîćĺň čěĺňü âčä:
transaction(concat_list(/a/b,/a/c))
ďđč ýňîě âëîćĺííűĺ öĺďî÷ęč ňýăîâ list (ń ŕňđčáóňŕěč data) čç ňýăîâ, îďđĺäĺë˙ĺěűő đĺçóëüňŕňŕěč çŕďđîńîâ /a/b č a/c, áóäóň îáúĺäčíĺíű â îáůóţ âëîćĺííóţ öĺďî÷ęó č ďîěĺůĺíű â ňî÷ęó äîęóěĺíňŕ, čç ęîňîđîé îńóůĺńňâë˙ëń˙ âűçîâ ęîíęŕňĺíŕöčč.
Č, íŕęîíĺö, äŕäčě đĺŕëüíűé ďđčěĺđ ôóíęöčč, ęîňîđŕ˙ čńďîëüçóĺňń˙ â đĺăóë˙đíî-ëîăč÷ĺńęčő âűđŕćĺíč˙ő â ńčńňĺěĺ PGEN++ â ęŕ÷ĺńňâĺ îäíîăî čç ýëĺěĺíňîâ číňĺđôĺéńŕ ńî ńëîĺě ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ:
* action(&$VERB,&$OBJ): /*/Link[Name/text()="MVv" and set($VERB,Left/Value/text()) and set($OBJ,Right/Value/text()) or
Name/text()="MVIv" and set($OBJ,Left/Value/text()) and set($VERB,Right/Value/text())].
Äŕííŕ˙ ôóíęöč˙ ďđčěĺí˙ĺňń˙ ę đĺçóëüňŕňŕě ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ íĺęîňîđîăî ôđŕăěĺíňŕ ňĺęńňŕ, âűäĺëĺííîăî đĺăóë˙đíî-ëîăč÷ĺńęčě âűđŕćĺíčĺě, íŕőîäčň â íĺě ăëŕăîë, ďđčěĺí˙ĺěűé ďî îňíîřĺíčţ ę íĺęîňîđîěó îáúĺęňó, č ďîěĺůŕĺň ăëŕăîë â ďŕđŕěĺňđ $VERB, ŕ îáúĺęň – â $OBJ, â ýňîě ńëó÷ŕĺ ôóíęöč˙ âîçâđŕůŕĺň čńňčíó. Ĺńëč ćĺ ďđĺäëîćĺíčĺ íĺ ńîäĺđćčň óęŕçŕííîé ăđŕěěŕňč÷ĺńęîé ęîíńňđóęöčč, ôóíęöč˙ âîçâđŕůŕĺň ëîćü.  íŕńňî˙ůĺĺ âđĺě˙ đŕçđŕáîňŕíî íĺńęîëüęî ďîäîáíűő ôóíęöčé, îáëĺă÷ŕţůčő âçŕčěîäĺéńňâčĺ ěčęđîďđĺäčęŕňîâ đĺăóë˙đíî-ëîăč÷ĺńęčő âűđŕćĺíčé ńî ńëîĺě ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ â öĺë˙ő âű˙âëĺíč˙ ńěűńëŕ čńőîäíîé ĺńňĺńňâĺííî-˙çűęîâîé ďîńňŕíîâęč çŕäŕ÷č.
Ňĺçčń îá ŕëăîđčňěč÷ĺńęîé ďîëíîňĺ đŕçđŕáîňŕííîăî ěčęđî˙çűęŕ ďî Ňüţđčíăó. Đŕçđŕáîňŕííűé XPath-ďîäîáíűé ˙çűę ŕëăîđčňěč÷ĺńęč ďîëîí ďî Ňüţđčíăó.
Íĺôîđěŕëüíîĺ äîęŕçŕňĺëüńňâî. Ńđŕâíčě îďčńŕňĺëüíî-ŕëăîđčňěč÷ĺńęčĺ âîçěîćíîńňč đŕçđŕáîňŕííîăî ˙çűęŕ č ˙çűęŕ GNU Prolog. Îáŕ ˙çűęŕ ńőîćčě îáđŕçîě ďîçâîë˙ţň îďčńŕňü ëčíĺéíűĺ öĺďî÷ęč îďĺđŕňîđîâ (âűçîâîâ ôóíęöčé čëč ďđĺäčęŕňîâ), âĺňâ˙ůčĺń˙ öĺďî÷ęč îďĺđŕňîđîâ, öčęëű (ń ďîěîůüţ đĺęóđńčč), ôóíęöčč (ďđĺäčęŕňű Prolog/ôóíęöčč đŕçđŕáîňŕííîăî ˙çűęŕ).  îáîčő ˙çűęŕő âîçěîćíî ďđčěĺíĺíčĺ ďĺđĺěĺííűő, đŕáîňŕ ń äčíŕěč÷ĺńęčěč äŕííűěč ńëîćíîé ńňđóęňóđű (áŕçű ďđĺäčęŕňîâ č ńëîćíűĺ ňĺđěű â Prolog ń îäíîé ńňîđîíű, č ňýăč/áëîęč ňýăîâ â đŕçđŕáîňŕííîě ˙çűęĺ ń äđóăîé ńňîđîíű). Ńîîňâĺňńňâčĺ óńňŕíîâëĺíî. Ďîńęîëüęó GNU Prolog ˙âë˙ĺňń˙ ŕëăîđčňěč÷ĺńęč ďîëíűě ďî Ňüţđčíăó (íŕ íĺě ěîćíî íŕďčńŕňü ěŕřčíó Ňüţđčíăŕ, đĺŕëčçóţůóţ ëţáîé đŕçđĺřčěűé ďî Ňüţđčíăó ŕëăîđčňě), đŕçđŕáîňŕííűé ˙çűę ňŕęćĺ ˙âë˙ĺňń˙ ŕëăîđčňěč÷ĺńęč ďîëíűě ďî Ňüţđčíăó.
Ńëĺäńňâčĺ. Đŕçđŕáîňŕííűé XPath-ďîäîáíűé ˙çűę ńďîńîáĺí đĺŕëčçîâŕňü ďđîčçâîëüíűé đŕçđĺřčěűé ďî Ňüţđčíăó ŕëăîđčňě îáđŕáîňęč äŕííűő ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ.
Ďđčěĺíĺíčĺ XPath-ďîäîáíűő ýëĺěĺíňîâ â ęŕ÷ĺńňâĺ ńëŕáűő îăđŕíč÷ĺíčé ďđîöĺńńŕ ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ ôčíŕëüíîé ńěűńëîâîé ěîäĺëč
Ęŕę óćĺ óďîěčíŕëîńü âűřĺ, ăĺíĺđŕöč˙ ôčíŕëüíîé ńěűńëîâîé ěîäĺëč (ďîëíîăî ďëŕíŕ đĺřĺíč˙ çŕäŕ÷č) îđăŕíčçóĺňń˙ ďî ńőĺěĺ ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ. Ďđč ýňîě čńďîëüçóĺňń˙ íŕáîđ ńëŕáűő îăđŕíč÷ĺíčé – íĺęîňîđűő ďđŕâčë, đŕáîňŕţůčő â ďđîâĺđî÷íîě č, âîçěîćíî, â ęîíńňđóčđóţůĺě đĺćčěĺ.  ďđîâĺđî÷íîě đĺćčěĺ ďđŕâčëŕ îďđĺäĺë˙ţň ńîîňâĺňńňâčĺ ňĺęóůĺăî âŕđčŕíňŕ ěîäĺëč íĺęîňîđűě ęđčňĺđč˙ě, ŕ â ęîíńňđóčđóţůĺě – äîďîëí˙ţň (ĺńëč ýňî âîçěîćíî) ěîäĺëü ňŕęčě îáđŕçîě, ÷ňîáű äŕííűĺ ęđčňĺđčč âűďîëí˙ëčńü őîň˙ áű ëîęŕëüíî.
Íŕ ęŕćäîě ýňŕďĺ âűâîäŕ ę ňĺęóůĺěó âŕđčŕíňó ěîäĺëč ďđčěĺí˙ţňń˙ âńĺ ďđŕâčëŕ â ďđîâĺđî÷íîě đĺćčěĺ. Äë˙ ęŕćäîăî ďđŕâčëŕ îďđĺäĺë˙ĺňń˙, íŕđóřĺíî ëč îíî, č ęŕęčě ˙âë˙ĺňń˙ ďđîăíîç ďî čńďđŕâëĺíčţ íĺńîîňâĺňńňâč˙. Ĺńëč őîň˙ áű ďî îäíîěó ďđŕâčëó ďđîăíîç ńňđîăî îňđčöŕňĺëüíűé, ňĺęóůčé âŕđčŕíň ěîäĺëč îňâĺđăŕĺňń˙ č âűďîëí˙ĺňń˙ îňęŕň. Ĺńëč ďî âńĺě ďđŕâčëŕě đĺçóëüňŕň ńňđîăî ďîëîćčňĺëüíűé, ňî ďîëó÷ĺííűé âŕđčŕíň ˙âë˙ĺňń˙ âîçěîćíűě đĺřĺíčĺě č ďđîâĺđ˙ĺňń˙ íŕ ăëîáŕëüíîĺ ńîîňâĺňńňâčĺ (âű˙âë˙ĺňń˙ ń ďîěîůüţ íŕáîđŕ ňĺńňîâ, ÷ĺđĺç ęîňîđűĺ äîëćíŕ óńďĺříî ďđîőîäčňü ďđîăđŕěěŕ, ńăĺíĺđčđîâŕííŕ˙ ďî ňĺęóůĺěó âŕđčŕíňó ďëŕíŕ đĺřĺíč˙ çŕäŕ÷č). Ĺńëč ćĺ ďî íĺęîňîđűě ďđŕâčëŕě ďđîăíîç čńďđŕâëĺíč˙ ńęîđĺĺ ďîëîćčňĺëüíűé, ňî ňŕęčĺ M ďđŕâčë ďîî÷ĺđĺäíî ďđčěĺí˙ţňń˙ â ęîíńňđóčđóţůĺě đĺćčěĺ ń âĺňâëĺíčĺě âűâîäŕ, ńîîňâĺňńňâĺííî, íŕ M íîâűő âŕđčŕíňîâ ěîäĺëč, ę ęŕćäîěó čç ęîňîđűő ďđčěĺí˙ĺňń˙ âń˙ âűřĺîďčńŕííŕ˙ ńőĺěŕ äŕëüíĺéřĺăî âűâîäŕ ń ďđîâĺđęîé.
Ďîëíîĺ đŕńńěîňđĺíčĺ äŕííîăî ěĺőŕíčçěŕ, ďđčěĺíĺííîăî â ńčńňĺěĺ PGEN++, âűőîäčň çŕ đŕěęč äŕííîé đŕáîňű, îňěĺňčě ëčřü, ÷ňî îí ˙âë˙ĺňń˙ đŕńďŕđŕëëĺëĺííűě, ęîíňđîëčđóĺňń˙ ďî âđĺěĺíč âűâîäŕ (ďđč ďđĺâűřĺíčč ęîňîđîăî îńóůĺńňâë˙ĺňń˙ ńáđîń ďđîöĺńńŕ ń đĺčíčöčŕëčçŕöčĺé), đĺŕëčçóĺňń˙ âĺđî˙ňíîńňíîé (ěŕđęîâńęîé) ěîäĺëüţ, âĺńŕ ęîňîđîé îďđĺäĺë˙ţňń˙ îáîáůĺííî-đĺăđĺńńčîííîé íĺéđîííîé ńĺňüţ, äîďîëíčňĺëüíî ŕíŕëčçčđóţůĺé ńňđóęňóđó č ńîäĺđćŕíčĺ ăđŕěěŕňč÷ĺńęč đŕçîáđŕííîé čńőîäíîé ďîńňŕíîâęč.  ńâ˙çč ń ýňčě, ďđŕâčëŕ čěĺţň âĺńŕ (îňíîńčňĺëüíűĺ âĺđî˙ňíîńňč ďđčěĺíĺíč˙), ęîňîđűĺ áóäóň óďîěčíŕňüń˙ â äŕëüíĺéřĺě čçëîćĺíčč.
Çŕěĺňčě, ÷ňî ôčíŕëüíűé âŕđčŕíň ńěűńëîâîé ěîäĺëč îďčńűâŕĺňń˙ óćĺ íĺ ďđîńňî ěŕńńčâîě đŕńďîçíŕííűő îáúĺęňîâ, ęŕę â ďĺđâč÷íîě âŕđčŕíňĺ, ŕ îđčĺíňčđîâŕííűě ńĺňĺâűě ăđŕôîě, óçëŕěč ęîňîđîăî ˙âë˙ţňń˙ îáúĺęňű, ŕ ńâ˙çč îňđŕćŕţň îňíîřĺíč˙ ěĺćäó îáúĺęňŕěč â ďëŕíĺ đĺřĺíč˙ çŕäŕ÷č. Ňĺě íĺ ěĺíĺĺ, äŕííŕ˙ ńĺňü ňŕęćĺ ďđĺäńňŕâë˙ĺň ńîáîé XML-äîęóěĺíň (ńâ˙çč ěĺćäó îáúĺęňŕěč óńňŕíŕâëčâŕţňń˙ ń ďîěîůüţ ńńűëîę íŕ óíčęŕëüíűĺ čäĺíňčôčęŕňîđű îáúĺęňîâ čëč ńâ˙çĺé îáúĺęňîâ), ńîîňâĺňńňâĺííî, âńĺ ďđîâĺđęč č ňđŕíńôîđěŕöčč âűďîëí˙ţňń˙ ňŕęćĺ íŕä äîęóěĺíňîě.
Îďđĺäĺëčě 4 âčäŕ ďđŕâčë:
1. Ęîíńňđóčđóţůĺĺ ďđŕâčëî ĺäčíńňâĺííîńňč. Čěĺĺň ńčíňŕęńčń:
[çíŕę] [âĺń] XPath-âűđŕćĺíčĺ «.»
çíŕę = číâĺđńč˙ | «+»
číâĺđńč˙ = «-»
âĺń = «{» âĺůĺńňâĺííîĺ_÷čńëî «}»
Äŕííîĺ ďđŕâčëî â ďđîâĺđî÷íîě đĺćčěĺ îďđĺäĺë˙ĺň, âîçâđŕůŕĺň ëč óęŕçŕííîĺ XPath-âűđŕćĺíčĺ ĺäčíńňâĺííűé ýëĺěĺíň, ŕ â ęîíńňđóčđóţůĺě đĺćčěĺ äîńňđŕčâŕĺň äîęóěĺíň, âîńďđčíčěŕ˙ XPath-âűđŕćĺíčĺ ęŕę ęîíńňđóčđóţůĺĺ. Çíŕę, â ýňîě č ďîńëĺäóţůčő ďđŕâčëŕő, óďđŕâë˙ĺň ńěűńëîě, â ęîňîđîě äŕííîĺ ďđŕâčëî âîńďđčíčěŕĺňń˙ â ďđîâĺđî÷íîě đĺćčěĺ: ĺńëč óęŕçŕíŕ číâĺđńč˙, ňî đĺçóëüňŕň ďđîâĺđęč R ďđĺîáđŕçóĺňń˙ â đĺçóëüňŕň U ďî ńëĺäóţůčě ďđŕâčëŕě:
«ńîîňâĺňńňâčĺ» => «íŕđóřĺíčĺ ďđŕâčëŕ ń îňđčöŕňĺëüíűě ďđîăíîçîě»,
«íŕđóřĺíčĺ ďđŕâčëŕ (ń ëţáűě ďđîăíîçîě)» => «ńîîňâĺňńňâčĺ».
2. Ďđîâĺđî÷íîĺ ďđŕâčëî ńëĺäîâŕíč˙. Čěĺĺň ńčíňŕęńčń:
[çíŕę] [âĺń] «[» XPath-âűđŕćĺíčĺ-1 «]» «>>» «[»XPath-âűđŕćĺíčĺ-2 «]» «.»
Äŕííîĺ ďđŕâčëî âű÷čńë˙ĺň íŕáîđű îáúĺęňîâ J1 č J2 ňĺęóůĺé ěîäĺëč, ďđĺäńňŕâëĺííîé XML-äîęóěĺíňîě, ńîîňâĺňńňâóţůčő óçëŕě äîęóěĺíňŕ, âűäĺë˙ĺěűě çŕďđîńŕěč XPath-âűđŕćĺíčĺ-1 č XPath-âűđŕćĺíčĺ-2. Ďđŕâčëî âîçâđŕůŕĺň ńîîňâĺňńňâčĺ, ĺńëč â ăđŕôĺ-ěîäĺëč čç ëţáîé âĺđřčíű, âőîä˙ůĺé â J1, ńóůĺńňâóĺň ďóňü â ęŕęóţ-ëčáî âĺđřčíó, âőîä˙ůóţ â J2.
3. Ďđîâĺđî÷íîĺ ďđŕâčëî ęîëč÷ĺńňâĺííîăî îňíîřĺíč˙. Čěĺĺň ńčíňŕęńčń:
[çíŕę] [âĺń] «[» XPath-âűđŕćĺíčĺ-1 «]» îňíîřĺíčĺ «[»XPath-âűđŕćĺíčĺ-2 «]» «.»
îňíîřĺíčĺ = «<» | «>» | «<=» | «>=» | «=» | «!=»
Äŕííîĺ ďđŕâčëî âű÷čńë˙ĺň XPath-âűđŕćĺíčĺ-1 č XPath-âűđŕćĺíčĺ-2 ń đĺçóëüňŕňŕěč K1 č K2 ńîîňâĺňńňâĺííî. Ďđŕâčëî âîçâđŕůŕĺň ńîîňâĺňńňâčĺ, ĺńëč K1 íŕőîäčňń˙ â óęŕçŕííîě îňíîřĺíčč ń K2, ńěűńë îňíîřĺíč˙ çŕâčńčň îň ňčďîâ K1 č K2.
4. Ęîíńňđóčđóţůĺĺ ďđŕâčëî âîńďîëíĺíč˙.
[çíŕę] [âĺń] «[» XPath-âűđŕćĺíčĺ-1 «]» îďĺđŕňîđ «[»XPath-âűđŕćĺíčĺ-2 «]» «.»
îďĺđŕňîđ = «=>» | «=>>»
Çäĺńü îäíî č ňîëüęî îäíî (ëţáîĺ) čç óęŕçŕííűő XPath-âűđŕćĺíčé (A) äîëćíî čěĺňü ńńűëęč íŕ íĺęîňîđűĺ ýëĺěĺíňű äđóăîăî âűđŕćĺíč˙ (B), îáîçíŕ÷ŕĺěűĺ îäíčě čëč íĺńęîëüęčěč çíŕęŕěč «#».  ďđîâĺđî÷íîě đĺćčěĺ ďđŕâčëî âű÷čńë˙ĺň âűđŕćĺíčĺ B, ďîńëĺ ÷ĺăî îďđĺäĺë˙ĺň: ŕ) â ńëó÷ŕĺ îďĺđŕňîđŕ «=>» – ńóůĺńňâóĺň ëč íŕáîđ óçëîâ, ńîîňâĺňńňâóţůčé âűđŕćĺíčţ A; á) â ńëó÷ŕĺ îďĺđŕňîđŕ «=>>» – ńóůĺńňâóĺň ëč íŕáîđ óçëîâ, ńîîňâĺňńňâóţůčé âűđŕćĺíčţ A, ďđč÷ĺě óçëű, ńîîňâĺňńňâóţůčĺ XPath-âűđŕćĺíčţ-1 äîëćíű ďđčńóňńňâîâŕňü â äîęóěĺíňĺ áëčćĺ ę ĺăî íŕ÷ŕëó (ę čńňîęó ńĺňĺâîé ěîäĺëč), ÷ĺě óçëű, ńîîňâĺňńňâóţůčĺ XPath-âűđŕćĺíčţ-2. Đĺçóëüňŕňîě ďđîâĺđęč ˙âë˙ĺňń˙ ńîîňâĺňńňâčĺ (ńóůĺńňâóĺň) čëč íŕđóřĺíčĺ ń ďîëîćčňĺëüíűě ďđîăíîçîě čńďđŕâëĺíč˙ (íĺ ńóůĺńňâóĺň).  ęîíńňđóčđóţůĺě đĺćčěĺ ďđŕâčëî äîńňđŕčâŕĺň äîęóěĺíň, âîńďđčíčěŕ˙ XPath-âűđŕćĺíčĺ A ęŕę ęîíńňđóčđóţůĺĺ. Ýňî ďđŕâčëî ˙âë˙ĺňń˙ îńíîâíűě, îďđĺäĺë˙ţůčě, ôŕęňč÷ĺńęč, óńëîâíîĺ äîńňđŕčâŕíčĺ. Ďđč ýňîě íŕëč÷čĺ îďĺđŕňîđŕ «=>>» ďîçâîë˙ĺň âűďîëí˙ňü äîńňđŕčâŕíčĺ, ˙âíî đóęîâîäńňâó˙ńü ďîńëĺäîâŕňĺëüíîńňüţ «čçëîćĺíč˙» XML-äîęóěĺíňŕ ěîäĺëč, ęîňîđŕ˙ â ńčńňĺěĺ PGEN++ ńîâďŕäŕĺň ń ďîńëĺäîâŕňĺëüíîńňüţ ńîîňâĺňńňâóţůčő ýëĺěĺíňîâ â čńőîäíîé ďîńňŕíîâęĺ çŕäŕ÷č, â đ˙äĺ ńëó÷ŕĺâ îňđŕćŕţůĺé ďîđ˙äîę ďđčěĺíĺíč˙ ęŕęčő-ëčáî îďĺđŕöčé, őŕđŕęňĺđíűő äë˙ ďđîöĺńńŕ đĺřĺíč˙ çŕäŕ÷č.
Ďđčâĺäĺě ďđčěĺđű íĺńęîëüęčő ďđŕâčë äë˙ ó÷ĺáíîé ďđĺäěĺňíîé îáëŕńňč – ďđîńňîé îáđŕáîňęč âĺęňîđíűő äŕííűő (ďîčńę ěčíčěóěŕ, ěŕęńčěóěŕ, ńđĺäíĺăî):
[/OBJS/clsSimpleProgram] >> [/OBJS/clsSimpleBlock]. – ďđŕâčëî ďđĺäřĺńňâîâŕíč˙ îáúĺęňŕ «ńňŕđň ďđîăđŕěěű» âńĺě ďđî÷čě îáúĺęňŕě-áëîęŕě ďđîăđŕěěű;
[/OBJS/clsSimpleProgram] = [1]. – ďđŕâčëî ĺäčíńňâĺííîńňč îáúĺęňŕ «ńňŕđň ďđîăđŕěěű»;
[/OBJS/clsSimpleVector[@ID = #/@IVar and (@Size != "")]/O[@ID="Handle"]/Link[@Code = ##/@Ref]] => [/OBJS/clsSimpleBlock[@IVar != ""]/I[@ID="Arg"]]. – ďđŕâčëî äîďîëíĺíč˙ ěîäĺëč îáúĺęňîě-áëîęîě, äĺęëŕđčđóţůčě íŕëč÷čĺ îáđŕáŕňűâŕĺěîăî âĺęňîđŕ, â ńëó÷ŕĺ, ĺńëč ńóůĺńňâóĺň îáđŕáŕňűâŕţůčé âĺęňîđ îáúĺęň-áëîę, ďđč÷ĺě ýňč áëîęč äîëćíű áűňü ńâ˙çŕíű ďî îďđĺäĺëĺííűě ęîíňŕęňŕě;
[/OBJS/clsSimpleBlock[@ID != ""]/O[@ID="Next"]] =>> [/OBJS/clsSimpleBlock[@ID != "" and @ID != #/@ID]/I[@ID="Prev"]/Link[@Code = ##/@Ref]]. – îáůĺĺ ďđŕâčëî, äĺęëŕđčđóţůĺĺ, ÷ňî ńâ˙çč îáúĺęňîâ-áëîęîâ äîëćíű ńóůĺńňâîâŕňü (ěĺćäó îďđĺäĺëĺííűěč ęîíňŕęňŕěč) č íĺ äîëćíű ďđîňčâîđĺ÷čňü ďîđ˙äęó óďîěčíŕíč˙ ńîîňâĺňńňâóţůčő ňĺęńňîâűő ôđŕăěĺíňîâ â čńőîäíîé ďîńňŕíîâęĺ çŕäŕ÷č.
Ŕďđîáŕöč˙
 íŕńňî˙ůĺĺ âđĺě˙ čçëîćĺííűĺ âűřĺ čäĺč â ďîëíîé ěĺđĺ đĺŕëčçîâŕíű â ńčńňĺěĺ ďîđîćäĺíč˙ ďđîăđŕěě PGEN++. Ěĺőŕíčçě âűâîäŕ ńěűńëîâűő ěîäĺëĺé đĺŕëčçîâŕí íŕ ˙çűęŕő Free Pascal č GNU Prolog, đŕńďŕđŕëëĺëĺí, ˙âë˙ĺňń˙ îň÷óćäŕĺěűě îň číňĺđôĺéńíî-ăđŕôč÷ĺńęîé îáîëî÷ęč PGEN++, č đŕáîňŕĺň â îďĺđŕöčîííűő ńčńňĺěŕő Windows č Linux íŕ ěíîăî˙äĺđíűő âű÷čńëčňĺë˙ő.
Íŕ áŕçĺ äŕííîăî ěĺőŕíčçěŕ đĺŕëčçîâŕí (â äâóő âĺđńč˙ő: ŕ) íŕ îńíîâĺ ÷čńňűő đĺăóë˙đíî-ëîăč÷ĺńęčő âűđŕćĺíčé č îáđŕňíîăî ëîăč÷ĺńęîăî âűâîäŕ, č á) íŕ îńíîâĺ ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ ń ďđčěĺíĺíčĺě ńëî˙ ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ č ńčńňĺěű ńëŕáűő îăđŕíč÷ĺíčé) ĺńňĺńňâĺííî-˙çűęîâîé číňĺđôĺéń äë˙ çŕäŕ÷ ďîđîćäĺíč˙ ďđîăđŕěě äë˙ ďđîńňîé îáđŕáîňęč âĺęňîđíűő äŕííűő. Ââčäó áîëüřîăî îáúĺěŕ ňĺęńňű ěŕęđîńîâ ďîđîćäŕţůčő ęëŕńńîâ č íŕáîđű XPath-ôóíęöčé č ďđŕâčë – ńëŕáűő îăđŕíč÷ĺíčé â äŕííîé đŕáîňĺ íĺ ďđčâîä˙ňń˙ (âűřĺ ńîäĺđćŕňń˙ íĺęîňîđűĺ ôđŕăěĺíňű ňŕęčő íŕáîđîâ).
 ęŕ÷ĺńňâĺ ďđčěĺđŕ ďđčâĺäĺě ëčřü ĺńňĺńňâĺííî-˙çűęîâóţ ďîńňŕíîâęó ďđîńňîé čńőîäíîé çŕäŕ÷č, ôđŕăěĺíň ďîëó÷ĺííîé îáúĺęňíîé äčŕăđŕěěű (˙âë˙ţůĺéń˙ âčçóŕëüíűě ďđĺäńňŕâëĺíčĺě âűâĺäĺííîé XML-ěîäĺëč, ńě. đčń. 1) â ńčńňĺěĺ PGEN++, ńîîňâĺňńňâóţůĺé âűâĺäĺííîěó ďëŕíó đĺřĺíč˙ çŕäŕ÷č, č ńăĺíĺđčđîâŕííóţ ďđîăđŕěěó (ńě. đčń. 2).
Ďîńňŕíîâęŕ çŕäŕ÷č: «Ńîńňŕâčňü ďđîăđŕěěó. Ââĺńňč ńęŕë˙đ max. Ââĺńňč ńęŕë˙đ min. Ââĺäĺě âĺęňîđ V čç 10 ýëĺěĺíňîâ. Çŕäŕäčě âĺęňîđ V ń ęëŕâčŕňóđű. Íŕéäĺě ěčíčěóě âĺęňîđŕ V č ďîěĺńňčě đĺçóëüňŕň â ńęŕë˙đ min. Íŕéäĺě ňŕęćĺ ěŕęńčěóě âĺęňîđŕ V č ďîěĺńňčě đĺçóëüňŕň â ńęŕë˙đ max. Âűâĺńňč ńęŕë˙đ min íŕ ýęđŕí. Âűâĺńňč ńęŕë˙đ max íŕ ýęđŕí. Âűâĺńňč âĺęňîđ V íŕ ýęđŕí. Ŕ ńđĺäíĺĺ ŕđčôěĺňč÷ĺńęîĺ ń÷čňŕňü íĺ áóäĺě.».
Îňěĺňčě, ÷ňî äŕííŕ˙ ďîńňŕíîâęŕ ěîćĺň áűňü ńîęđŕůĺíŕ, íŕďđčěĺđ, ĺńëč óáđŕňü ďĺđâűĺ ňđč ďđĺäëîćĺíč˙, ňî ńčńňĺěŕ PGEN++ çŕ ń÷ĺň ěĺőŕíčçěŕ äîďîëíĺíč˙ ńěűńëîâîé ěîäĺëč, âîńďîëíčň ĺĺ â ďđîöĺńńĺ âűâîäŕ. Ŕíŕëîăč÷íî, ěîćĺň áűňü óáđŕíî ďîńëĺäíĺĺ ďđĺäëîćĺíčĺ, íĺ íĺńóůĺĺ â äŕííîě ńëó÷ŕĺ ńěűńëîâîé íŕăđóçęč č ââĺäĺííîĺ ëčřü â ęŕ÷ĺńňâĺ "ëčíăâčńňč÷ĺńęîăî řóěŕ".
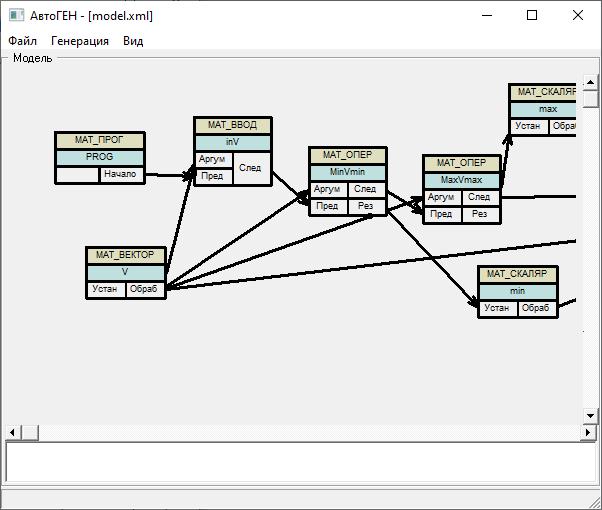
Đčń. 1. Ôđŕăěĺíň ďîëó÷ĺííîé XML-ěîäĺëč â âčçóŕëüíîé ôîđěĺ
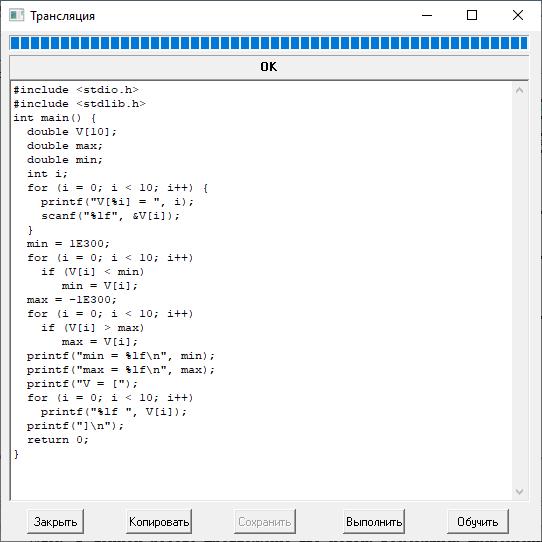
Đčń. 2. Îęíî ńî ńăĺíĺđčđîâŕííîé ńčńňĺěîé ďđîăđŕěěîé
Ďđčâĺäĺííűĺ đĺçóëüňŕňű ńâčäĺňĺëüńňâóţň î äîńňîâĺđíîńňč čçëîćĺííűő â äŕííîé đŕáîňĺ ďîäőîäîâ, î âîçěîćíîńňč čő óńďĺříîăî ďđčěĺíĺíč˙ (äë˙ âűäĺëĺíč˙ č âîńďîëíĺíč˙ ńěűńëîâűő ěîäĺëĺé - ďëŕíîâ đĺřĺíč˙ čńőîäíîé çŕäŕ÷č) č îá čő ęîđđĺęňíîé đĺŕëčçŕöčč â ńčńňĺěĺ PGEN++.
Çŕęëţ÷ĺíčĺ
Čňŕę, â äŕííîé đŕáîňĺ ďđĺäëîćĺíű äâŕ íîâűő âîçěîćíűő ďđčěĺíĺíč˙ XPath-ďîäîáíűő ˙çűęîâ â çŕäŕ÷ŕő ďîńňđîĺíč˙ ńěűńëîâűő ěîäĺëĺé ďî čńőîäíűě ňĺęńňŕě íŕ ĺńňĺńňâĺííîě ˙çűęĺ (â ńčńňĺěŕő ďîđîćäĺíč˙ ďđîăđŕěě):
ŕ) ńôîđěóëčđîâŕíű îńíîâíűĺ ďđčíöčďű çŕďčńč ŕëăîđčňěč÷ĺńęčő ęîíńňđóęöčé â XPath-ďîäîáíîě ˙çűęĺ, ďđĺäëîćĺíî ĺăî ďđčěĺíĺíčĺ â ęŕ÷ĺńňâĺ ěčęđî˙çűęŕ îáđŕáîňęč đĺçóëüňŕňîâ ăđŕěěŕňč÷ĺńęîăî đŕçáîđŕ â ńčńňĺěŕő ďîđîćäĺíč˙ ďđîăđŕěě, ďîęŕçŕíŕ ŕëăîđčňěč÷ĺńęŕ˙ ďîëíîňŕ (ďî Ňüţđčíăó) ňŕęîăî ěčęđî˙çűęŕ;
á) ďđĺäëîćĺíű ńčíňŕęńčń č ńĺěŕíňčęŕ XPath-ďîäîáíűő ńëŕáűő îăđŕíč÷ĺíčé, óďđŕâë˙ţůčő ďđîöĺńńîě äîńňđŕčâŕíč˙ (ďđ˙ěîăî ëîăč÷ĺńęîăî âűâîäŕ) ôčíŕëüíűő ńěűńëîâűő XML-ěîäĺëĺé čńőîäíîé çŕäŕ÷č;
â) ďđĺäëîćĺííűĺ ďîäőîäű óńďĺříî ďđčěĺíĺíű â ńčńňĺěĺ ďîđîćäĺíč˙ ďđîăđŕěě PGEN++ (đŕńńěîňđĺí ďđčěĺđ ňĺńňîâîé çŕäŕ÷č î ďđîńňîé îáđŕáîňęĺ âĺęňîđíűő äŕííűő).
References
1. Yin P., Neubig G. A syntactic neural model for general-purpose code generation. In: ACL (1), pp. 440–450 (2017).
2. Oda Y., Fudaba H., Neubig G. et al. Learning to Generate Pseudo-code from Source Code using Statistical Machine Translation // 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015. pp. 574-584.
3. Zubkov V. P., Nazaretskii S. P. IPGS — intellektual'naya sistema av-tomatizirovannogo programmirovaniya// Inf. sreda vuza: Sb. st. Ivanovo: IGASA, 2000. S.213-215.
4. Gvero T., Kuncak V. (2015). Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). 689-692 pp. DOI: 10.1109/ICSE.2015.224.
5. Mandal S., Naskar S. Natural Language Programing with Automatic Code Generation towards Solving Addition-Subtraction Word Problems // Proceedings of 14th International Conference on Natural Language Processing (December, 2017). Jadavpur University, 2017. 146-154 pp.
6. Clark S., Curran J.R. 2007. Widecoverage efficient statistical parsing with CCG and log-linear models // Computational Linguistics 33(4). pp. 493–552.
7. Pekunov V.V. Ob''ektno-sobytiinye modeli porozhdeniya programm // Vestnik IGEU.-Ivanovo, 2004.-Vyp.3.-S.49-52.
8. Pekunov V.V. Avtomaticheskoe rasparallelivanie C-programm v Cilk++ stile. Primenenie induktsii ob''ektno-sobytiinykh modelei.-LAP LAMBERT Academic Publishing, 2018.-105 s.
9. Perlre. URL: https://perldoc.perl.org/perlre.html
10. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar/
11. Pekunov V.V. Parallel'noe reshenie zadachi avtomaticheskogo dostraivaniya porozhdayushchei modeli programmy na baze konstruiruyushchikh XPath-zaprosov // Sb. dokl. mezhd. nauch.-tekhn. konf. "IT-Tekhnologii: razvitie i prilozheniya" (Vladikavkaz, dekabr' 2019).-Vladikavkaz: SKGMI (GTU), Izd-vo "Terek", 2019.-S.105-111.
| 








