|
Software systems and computational methods
Reference:
Martyshenko N.S., Martyshenko S.N.
Algorithmization of the process of analyzing the reliability of online questionnaire data
// Software systems and computational methods.
2018. ą 4.
P. 76-85.
DOI: 10.7256/2454-0714.2018.4.28367 URL: https://en.nbpublish.com/library_read_article.php?id=28367
Algorithmization of the process of analyzing the reliability of online questionnaire data
Martyshenko Natal'ya Stepanovna
PhD in Economics
Professor, the department of International Marketing and Trade, Vladivostok State University of Economics and Service
690014, Russia, Primorsky Krai, Vladivostok, Gogolya Street 41

|
natalya.martyshenko@mail.ru
|
|
 |
Other publications by this author
|
|
|
Martyshenko Sergei Nikolaevich
PhD in Technical Science
Professor, Department of Mathematics and Modeling, Vladivostok State University of Economics and Service
690014, Russia, Primorskii krai, g. Vladivostok, pr. Krasnogo Znameni, 96, kv. 17
|
|
sergey.martishenko@vvsu.ru
|
|
 |
|
DOI: 10.7256/2454-0714.2018.4.28367
Received:
13-12-2018
Published:
10-01-2019
Abstract:
With the proliferation of online forms design services for online surveys, the number of researchers using questionnaires in research practice has increased significantly. One of the problems that was present in the traditional form of the survey on paper and was transferred to online surveys is the problem of data reliability. Most researchers using online surveys have higher queries to automate research. They are not ready to make significant efforts to increase the reliability of the data. In this paper, we propose to consider an algorithm for automating the process of analyzing the reliability of questionnaire data. The proposed algorithm is based on the use of a sliding exam procedure for testing individual multidimensional observations obtained during an online survey. The main hypothesis underlying the developed method consists in the fact that the subordination of the questionnaire questions to some general topic leads to some latent connections between answers that are violated by random answers. A multi-dimensional statistical criterion was developed for testing personal data. The method is very simple to use and is available even for not sophisticated researchers.
Keywords:
questionnaire, data quality, online survey, multivariate statistical methods, latent connections, criterion fquality of data, sliding exam, computer technology, Internet service, nominal features
Ââĺäĺíčĺ
 íŕńňî˙ůĺĺ âđĺě˙ â čńńëĺäîâŕíčč ńîöčŕëüíî-ýęîíîěč÷ĺńęčő ďđîöĺńńîâ âńĺ áîëüřĺĺ đŕńďđîńňđŕíĺíčĺ ďîëó÷ŕţň ŕíęĺňíűĺ îďđîńű [1].  áîëüřîé ńňĺďĺíč ýňî ńâ˙çŕíî ń đŕńďđîńňđŕíĺíčĺě îíëŕéí-îďđîńîâ, đĺŕëčçóĺěűő ń ďîěîůüţ đŕçëč÷íűő ńďĺöčŕëčçčđîâŕííűő ďđîăđŕěěíűő ńĺđâčńîâ, ďîçâîë˙ţůčő íĺ ňîëüęî ęîíńňđóčđîâŕňü îíëŕéí-îďđîńű, íî č îńóůĺńňâë˙ňü ňčďîâóţ îáđŕáîňęó äŕííűő [2-5]. Ńđĺäč đŕńďđîńňđŕíĺííűő îíëŕéí-ńĺđâčńîâ ěîćíî âűäĺëčňü ňŕęčĺ ńĺđâčńű: Google Forms, Survey Monkey, Survio, Typeform Simpoll č äđóăčĺ. Íîâűĺ ěĺňîäű ďđîčçâîäńňâŕ äŕííűő ňđĺáóţň đŕçđŕáîňęč áîëĺĺ ńîâĺđřĺííűő ěĺňîäîâ čő îáđŕáîňęč. Îäíîé čç ďđîáëĺě, ęîňîđŕ˙ ďđčńóňńňâîâŕëŕ ďđč ňđŕäčöčîííîé ôîđěĺ îďđîńŕ íŕ áóěŕćíîě íîńčňĺëĺ č ďĺđĺřëŕ č â îíëŕéí-îďđîńű, ˙âë˙ĺňń˙ ďđîáëĺěŕ äîńňîâĺđíîńňč äŕííűő. Ďđč îíëŕéí-îďđîńŕő ýňŕ ďđîáëĺěŕ äŕćĺ óńóăóáčëŕńü [6, 7]. Âî-ďĺđâűő, ńáîđ äŕííűő îńóůĺńňâë˙ĺňń˙ áĺç ďđ˙ěîăî ęîíňŕęňŕ ń číňĺđâüţĺđîě č ÷ŕůĺ âńĺăî ˙âë˙ĺňń˙ áîëĺĺ îáĺçëč÷ĺííűě. Âî-âňîđűő, âîçđîńëč îáúĺěű ńîáčđŕĺěűő äŕííűő. Â-ňđĺňüčő, îíëŕéí-îďđîń ďđčâĺë íĺ ňîëüęî ę ńîęđŕůĺíčţ âđĺěĺíč íŕ ńŕě îďđîń, íî č âđĺěĺíč, îňâîäčěîăî íŕ ďîëíűé öčęë îáđŕáîňęč äŕííűő. Â-÷ĺňâĺđňűő, áîëüřčíńňâî čńńëĺäîâŕňĺëĺé, ďđčěĺí˙ţůčő îíëŕéí-îďđîńű, čěĺţň áîëĺĺ âűńîęčĺ çŕďđîńű ę ŕâňîěŕňčçŕöčč čńńëĺäîâŕíčé. Îíč íĺ ăîňîâű ďđĺäďđčíčěŕňü çíŕ÷čňĺëüíűĺ óńčëč˙ äë˙ ďîâűřĺíč˙ äîńňîâĺđíîńňč äŕííűő. Ďđîáëĺěŕ ęŕ÷ĺńňâŕ äŕííűő, ďîëó÷ĺííűő ń ďîěîůüţ îíëŕéí-îďđîńîâ, ďîäíčěŕĺňń˙ âî ěíîăčő íŕó÷íűő ďóáëčęŕöč˙ő.  ęŕ÷ĺńňâĺ ďđčěĺđŕ çŕđóáĺćíűő ďóáëčęŕöčé ěîćíî ďđčâĺńňč đŕáîňű [8-12]. Ńđĺäč đŕáîň đîńńčéńęčő ó÷ĺíűő ěîćíî âűäĺëčňü ńëĺäóţůčĺ ďóáëčęŕöčč [13-17]. Ŕâňîđŕěč áűë đŕçđŕáîňŕí đ˙ä ěĺňîäîâ ŕâňîěŕňčçŕöčč îáđŕáîňęč ŕíęĺňíűő äŕííűő, ęîňîđűĺ ďđîřëč ŕďđîáŕöčţ ďđč ŕíŕëčçĺ äŕííűő ŕíęĺňíűő îďđîńîâ, ďđîâîäčěűő ęŕę â îíëŕéí, ňŕę č îôëŕéí đĺćčěŕő [18, 19].  íŕńňî˙ůĺé đŕáîňĺ ďđĺäëŕăŕĺňń˙ ę đŕńńěîňđĺíčţ ŕëăîđčňě, ďîçâîë˙ţůčé ŕâňîěŕňčçčđîâŕňü ďđîöĺńń ŕíŕëčçŕ äîńňîâĺđíîńňč äŕííűő ŕíęĺňíűő îďđîńîâ. Ďđĺčěóůĺńňâî ŕëăîđčňěŕ ńîńňîčň â ňîě, ÷ňî îí ďîçâîë˙ĺň ŕíŕëčçčđîâŕňü âńţ (čëč ďî÷ňč âńţ) ńîâîęóďíîńňü äŕííűő, ďđĺäńňŕâëĺííűő â ŕíęĺňŕő.
Ďđĺäěĺň čńńëĺäîâŕíč˙
Ďđĺäěĺňîě čńńëĺäîâŕíčé ˙âë˙ţňń˙ äŕííűĺ, ďîëó÷ĺííűĺ â őîäĺ îíëŕéí ŕíęĺňíűő îďđîńîâ.
Ňŕęčĺ äŕííűĺ ôîđěčđóţň ěíîăîěĺđíűĺ âűáîđęč ďđčçíŕęîâ ňŕáëčö ńňŕňčńňč÷ĺńęčő äŕííűő, ęîňîđűĺ čńďîëüçóţňń˙ äë˙ ŕíŕëčçŕ ńîöčŕëüíî-ýęîíîěč÷ĺńęčő ďđîöĺńńîâ č ˙âëĺíčé.  áîëüřčíńňâĺ ŕíęĺňíűő ôîđě, ďđĺäńňŕâëĺííűő â číňĺđíĺň, â ęŕ÷ĺńňâĺ îńíîâíîăî ňčďŕ âîďđîńîâ čńďîëüçóţň âîďđîńű ń íŕáîđîě ŕëüňĺđíŕňčâíűő âŕđčŕíňîâ îňâĺňîâ. Ňŕęčĺ ŕíęĺňű ňđĺáóţň ěčíčěŕëüíîăî âđĺěĺíč çŕďîëíĺíč˙ č íŕčáîëĺĺ ďîí˙ňíű áîëüřčíńňâó đĺńďîíäĺíňîâ. Îňâĺňű íŕ ňŕęčĺ âîďđîńű ěîćíî ďđĺäńňŕâčňü â âčäĺ ňŕáëčöű îáúĺęň - ńâîéńňâî. Ńňđîęč ňŕáëčöű ďđĺäńňŕâë˙ţň ńîáîé íŕáëţäĺíč˙ (ŕíęĺňű), ŕ ńňîëáöű ŕńńîöččđîâŕíű ń îňäĺëüíűěč âîďđîńŕěč (ďđčçíŕęč).  ňŕęîě ćĺ âčäĺ ěîćíî ďđĺäńňŕâčňü âîďđîńű, ňđĺáóţůčĺ îňâĺňîâ ďî řęŕëĺ Ëŕéęĺđňŕ. Âîďđîńű, ňđĺáóţůčĺ çŕďîëíĺíč˙ ňŕáëčöű ňčďŕ «ńĺňęŕ ôëŕćęč», čěĺţň ŕíŕëîăč÷íóţ ôîđěó ďđĺäńňŕâëĺíč˙. Ęŕćäîěó ňŕęîěó âîďđîńó ńîîňâĺňńňâóĺň íĺńęîëüęî ńňîëáöîâ ňŕáëčöű äŕííűő ďî ęîëč÷ĺńňâó ńňđîę ňŕáëčöű ňčďŕ «ńĺňęŕ ôëŕćęč». Âńĺ ďĺđĺ÷čńëĺííűĺ âčäű čçěĺđĺíč˙ ěîćíî ďđč÷čńëčňü ę čçěĺđĺíč˙ě â íîěčíŕëüíîé řęŕëĺ.
Âńĺ áîëüřĺĺ đŕńďđîńňđŕíĺíčĺ â ŕíęĺňíűő îďđîńŕő íŕ÷číŕţň íŕőîäčňü îňęđűňűĺ âîďđîńű, ęîňîđűĺ čěĺţň íĺęîňîđűĺ ďđĺčěóůĺńňâî ďĺđĺä âîďđîńŕěč ń çŕäŕííűě íŕáîđîě ŕëüňĺđíŕňčâ. Ďîńëĺ îáđŕáîňęč ňŕęčő äŕííűő îíč ňîćĺ ěîăóň áűňü ďđčâĺäĺíű ę íîěčíŕëüíîé řęŕëĺ. Îáđŕáîňęŕ îňęđűňűő âîďđîńîâ îńíîâŕíŕ íŕ ďđčěĺíĺíčč îďĺđŕöčč ňčďčçŕöčč [8, 9]. ×čńëîâűĺ äŕííűĺ ňîćĺ ěîćíî ńâĺńňč ę îăđŕíč÷ĺííîěó ńďčńęó çíŕ÷ĺíčé ďóňĺě đŕíćčđîâŕíč˙ ďî çŕäŕííűě ăđŕíčöŕě číňĺđâŕëîâ çíŕ÷ĺíčé.
Äë˙ ôîđěŕëčçîâŕííîăî îďčńŕíč˙ ŕëăîđčňěŕ ââĺäĺě íĺęîňîđűĺ îáîçíŕ÷ĺíč˙. Ďóńňü ďđîčçâĺäĺíŕ âűáîđęŕ îáúĺěîě n (ęîëč÷ĺńňâî ŕíęĺň-ńňđîę â ňŕáëčöĺ äŕííűő). Îáîçíŕ÷čě ńîâîęóďíîńňü íîěčíŕëüíűő ďđčçíŕęîâ â ňŕáëčöĺ äŕííűő ęŕę
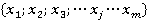 , ,
ăäĺ m – ęîëč÷ĺńňâî íîěčíŕëüíűő ďđčçíŕęîâ, 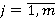 . .
Ýëĺěĺíňű ěíîćĺńňâŕ ěîćíî âîńďđčíčěŕňü ęŕę ńëó÷ŕéíűĺ ďĺđĺěĺííűĺ čëč čäĺíňčôčęŕňîđű íîěčíŕëüíűő ďđčçíŕęîâ. Áóäĺě ń÷čňŕňü, ÷ňî ęŕćäűé ńňîëáĺö äŕííűő ďđĺäńňŕâëĺí îăđŕíč÷ĺííűě íŕáîđîě (ěíîćĺńňâîě) çíŕ÷ĺíčé ďđčçíŕęŕ 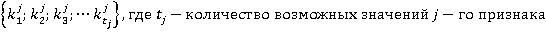 . Äë˙ óďđîůĺíč˙ çŕďčńč çŕěĺíčě ęîíęđĺňíűĺ çíŕ÷ĺíč˙ ďđčçíŕęŕ čő íîěĺđŕěč â ńďčńęĺ çíŕ÷ĺíčé ďđčçíŕęŕ. Ňîăäŕ ěíîćĺńňâî çíŕ÷ĺíčé ďđčçíŕęŕ j ěîćíî ďđĺäńňŕâčňü ěíîćĺńňâîě . Äë˙ óďđîůĺíč˙ çŕďčńč çŕěĺíčě ęîíęđĺňíűĺ çíŕ÷ĺíč˙ ďđčçíŕęŕ čő íîěĺđŕěč â ńďčńęĺ çíŕ÷ĺíčé ďđčçíŕęŕ. Ňîăäŕ ěíîćĺńňâî çíŕ÷ĺíčé ďđčçíŕęŕ j ěîćíî ďđĺäńňŕâčňü ěíîćĺńňâîě 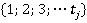 . .
Îńíîâíűĺ ďđčíöčďű đŕáîňű ŕëăîđčňěŕ
Đŕáîňŕ ŕëăîđčňěŕ îńíîâűâŕĺňń˙ íŕ âďîëíĺ đĺŕëčńňč÷íűő ďđĺäďîëîćĺíč˙ő (ăčďîňĺçŕő) îňíîńčňĺëüíî âűáîđęč, ńôîđěčđîâŕííîé ďî äŕííűě ŕíęĺňíîăî îďđîńŕ.
Ďĺđâŕ˙ ăčďîňĺçŕ ńîńňîčň â ďđĺäďîëîćĺíčč, ÷ňî îńíîâíŕ˙ ěŕńńŕ ŕíęĺňíűő äŕííűő îňâĺ÷ŕĺň ňđĺáîâŕíčţ äîńňîâĺđíîńňč. Ňî ĺńňü, áîëüřčíńňâî đĺńďîíäĺíňîâ ďîíčěŕëč ńóňü çŕäŕííűő âîďđîńîâ č îňâĺňńňâĺííî îňíîńčëčńü ę îňâĺňŕě íŕ âîďđîńű ŕíęĺňű.
Âňîđŕ˙ ăčďîňĺçŕ ńîńňîčň â ňîě, ÷ňî âîďđîńű ŕíęĺňű îáúĺäčíĺíű íĺęîňîđîé îáůĺé ňĺěŕňčęîé, ÷ňî íĺčçáĺćíî ďđčâîäčň ę âîçíčęíîâĺíčţ íĺęîňîđűő ëŕňĺíňíűő ńâ˙çĺé ěĺćäó îňâĺňŕěč. Ňî ĺńňü, äŕííűě ďđčńóůč íĺęîňîđűĺ ńňŕňčńňč÷ĺńęčĺ çŕęîíîěĺđíîńňč, îáóńëîâëĺííűĺ âíóňđĺííĺé ëîăčęîé ŕíęĺňű. Îňâĺňű íŕ îäíč âîďđîńű ŕíęĺňű âëč˙ţň â ńňŕňčńňč÷ĺńęîě ńěűńëĺ íŕ äđóăčĺ îňâĺňű. Ńëĺäó˙ ëîăčęĺ, îňâĺňű íŕ îňäĺëüíűĺ âîďđîńű ěîăóň áűňü ëčáî íĺńîâěĺńňčěű, ëčáî ěŕëîâĺđî˙ňíű. Íŕďđčěĺđ, ĺńëč đĺńďîíäĺíň â îäíîě âîďđîńĺ óęŕçűâŕĺň ÷ňî îí âĺăĺňŕđčŕíĺö, ŕ â äđóăîě ńđĺäč íŕčáîëĺĺ ÷ŕńňî çŕęŕçűâŕĺěűő čě áëţä â ńňîëîâîé óęŕçűâŕĺň ňîëüęî ě˙ńíűĺ áëţäŕ, ňî ňŕęčĺ îňâĺňű ďđîňčâîđĺ÷ŕň äđóă äđóăó. Čëč ĺńëč đĺńďîíäĺíň îňěĺ÷ŕĺň, ÷ňî îí âďîëíĺ çäîđîâ č äŕëĺĺ çŕěĺ÷ŕĺň, ÷ňî ňđŕňčň áîëüřčĺ äĺíüăč íŕ ëĺęŕđńňâŕ íŕ ëĺ÷ĺíčĺ, - ýňî âűăë˙äčň íĺëîăč÷íî. Íĺëîăč÷íűĺ îňâĺňű đĺńďîíäĺíňŕ ěîăóň áűňü âűçâŕíű č íĺďđĺäíŕěĺđĺííűě äĺéńňâčĺě, íŕďđčěĺđ, ďđč íĺäîďîíčěŕíčč âîďđîńŕ ŕíęĺňű. Îäíŕęî, ňŕęčĺ îňâĺňű âńĺ đŕâíî íĺëüç˙ ďđčçíŕňü äîńňîâĺđíűěč.
Íŕ îńíîâĺ äŕííűő ăčďîňĺç ěîćíî ďîďűňŕňüń˙ âűäĺëčňü ňŕęčĺ ŕíęĺňű, ęîňîđűĺ ďëîőî ńîăëŕńóţňń˙ ń îáůčěč çŕęîíîěĺđíîńň˙ěč, ďđčńóůčěč âűáîđęĺ.
Đŕáîňŕ ŕëăîđčňěŕ îđăŕíčçîâŕíŕ ďî ďđčíöčďó ńęîëüç˙ůĺăî ýęçŕěĺíŕ. Ęŕćäîĺ íŕáëţäĺíčĺ ňĺńňčđóĺňń˙ ń ďîěîůüţ îďđĺäĺëĺííîăî ęđčňĺđč˙. Ęđčňĺđčé ďîńňđîĺí íŕ îöĺíęĺ đŕçíčöű ěĺćäó îňäĺëüíűě íŕáëţäĺíčĺě č ńîâîęóďíîńňüţ íŕáëţäĺíčé îńňŕâřĺéń˙ âűáîđęîé. Ďîńëĺ đŕń÷ĺňŕ ęđčňĺđč˙ äë˙ îäíîăî íŕáëţäĺíč˙ îíî âîçâđŕůŕĺňń˙ â âűáîđęó, ŕ čç íĺĺ čçűěŕĺňń˙ ńëĺäóţůĺĺ íŕáëţäĺíčĺ äë˙ ňĺńňčđîâŕíč˙. Ęđčňĺđčé ó÷čňűâŕĺň ëŕňĺíňíűĺ ńâ˙çč ěĺćäó âńĺěč ďŕđŕěč ďđčçíŕęîâ.
Óďîđ˙äî÷čâ çíŕ÷ĺíčĺ ęđčňĺđč˙ ěîćíî âűäĺëčňü «ďîäîçđčňĺëüíűĺ» íŕáëţäĺíč˙ (ŕíęĺňű), ęîňîđűĺ âűďŕäŕţň čç îáůĺăî đ˙äŕ íŕáëţäĺíčé. Âűäĺëĺííűĺ «ďîäîçđčňĺëüíűĺ» ŕíęĺňű íĺ îňáđŕńűâŕţňń˙ ŕâňîěŕňč÷ĺńęč, ŕ ďîäâĺđăŕţňń˙ äîďîëíčňĺëüíîěó ńîäĺđćŕňĺëüíîěó ŕíŕëčçó ďî îöĺíęĺ ďđŕâäîďîäîáč˙ îňâĺňîâ íŕ âîďđîńű ŕíęĺňű ń öĺëüţ âű˙ńíĺíč˙ ďđč÷čí âűäĺëĺíč˙ ňŕęčő ŕíęĺň â đ˙äó ďđî÷čő. Č ňîëüęî ďîńëĺ óńňŕíîâëĺíč˙ ňîăî, ÷ňî ňŕęčĺ ŕíęĺňű íĺëüç˙ ďđčçíŕňü äîńňîâĺđíűěč, ňŕęčĺ ŕíęĺňű îňáđŕńűâŕţňń˙.
Ďđčěĺđ đŕń÷ĺňŕ ęđčňĺđč˙ îöĺíęč äîńňîâĺđíîńňč äŕííűő ŕíęĺňíîăî îďđîńŕ
Ŕëăîđčňě đŕń÷ĺňŕ ęđčňĺđč˙ đŕńńěîňđčě íŕ ďđčěĺđĺ ěîäĺëüíűő äŕííűő. Îáúĺě ěîäĺëüíîé âűáîđęč ńîńňŕâë˙ĺň 101 íŕáëţäĺíčĺ (n=101). Âűáîđęŕ ďđĺäńňŕâëĺíŕ ď˙ňüţ íîěčíŕëüíűěč ďđčçíŕęŕěč 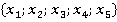 . Äë˙ ďđîńňîňű ďđĺäďîëîćčě, ÷ňî ęîëč÷ĺńňâî âîçěîćíűő çíŕ÷ĺíčé âńĺő ďđčçíŕęîâ îäčíŕęîâî.  ďđčěĺđĺ ďđčí˙ňî . Äë˙ ďđîńňîňű ďđĺäďîëîćčě, ÷ňî ęîëč÷ĺńňâî âîçěîćíűő çíŕ÷ĺíčé âńĺő ďđčçíŕęîâ îäčíŕęîâî.  ďđčěĺđĺ ďđčí˙ňî 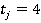 . Ń÷čňŕĺňń˙, ÷ňî ďđĺäâŕđčňĺëüíî âűáîđęŕ íîěčíŕëüíűő çíŕ÷ĺíčé ďđčçíŕęîâ áűëŕ ďđĺîáđŕçîâŕíŕ ďóňĺě çŕěĺíű âîçěîćíűő çíŕ÷ĺíčé ďđčçíŕęîâ čő íîěĺđŕěč â ńďčńęĺ. Ňî ĺńňü, . Ń÷čňŕĺňń˙, ÷ňî ďđĺäâŕđčňĺëüíî âűáîđęŕ íîěčíŕëüíűő çíŕ÷ĺíčé ďđčçíŕęîâ áűëŕ ďđĺîáđŕçîâŕíŕ ďóňĺě çŕěĺíű âîçěîćíűő çíŕ÷ĺíčé ďđčçíŕęîâ čő íîěĺđŕěč â ńďčńęĺ. Ňî ĺńňü, 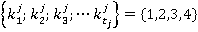 äë˙ âńĺő ďđčçíŕęîâ. äë˙ âńĺő ďđčçíŕęîâ.
Äë˙ íŕăë˙äíîńňč đŕń÷ĺňű, ďîëíîńňüţ ńîâďŕäŕţůčĺ, ěíîăîěĺđíűĺ íŕáëţäĺíč˙ âűáîđęč (ŕíęĺňű) áűëč ńăđóďďčđîâŕíű. Äë˙ ęŕćäîé óíčęŕëüíîé ďîńëĺäîâŕňĺëüíîńňč çíŕ÷ĺíčé ďđčçíŕęîâ áűëŕ đŕńń÷čňŕíŕ «÷ŕńňîňŕ âńňđĺ÷ŕĺěîńňč â âűáîđęĺ» Qs, (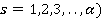 , ăäĺ , ăäĺ 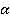 – ęîëč÷ĺńňâî óíčęŕëüíűő ŕíęĺň, âńňđĺ÷ŕâřčőń˙ â âűáîđęĺ – ęîëč÷ĺńňâî óíčęŕëüíűő ŕíęĺň, âńňđĺ÷ŕâřčőń˙ â âűáîđęĺ 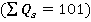 .  íŕřĺě ďđčěĺđĺ .  íŕřĺě ďđčěĺđĺ 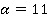 Ńăđóďďčđîâŕííŕ˙ âűáîđęŕ ďđĺäńňŕâëĺíŕ â ęîěďŕęňíîě âčäĺ â ňŕáëčöĺ 1. Ńăđóďďčđîâŕííŕ˙ âűáîđęŕ ďđĺäńňŕâëĺíŕ â ęîěďŕęňíîě âčäĺ â ňŕáëčöĺ 1.
Ňŕáëčöŕ 1. Ńăđóďďčđîâŕííŕ˙ âűáîđęŕ ěîäĺëüíűő äŕííűő
|
Íîěĺđ óíčęŕëüíîé
ďîńëĺäîâŕňĺëüíîńňč
îňâĺňîâ
|
Çíŕ÷ĺíč˙ ďđčçíŕęîâ âűáîđęč
|
×ŕńňîňŕ âńňđĺ÷ŕĺěîńňč â âűáîđęĺ Qs
|
Çíŕ÷ĺíčĺ ęđčňĺđč˙
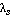
|
|
x1
|
x2
|
x3
|
x4
|
x5
|
|
1
|
1
|
1
|
4
|
3
|
1
|
21
|
0,790
|
|
2
|
1
|
1
|
4
|
3
|
2
|
19
|
0,902
|
|
3
|
1
|
1
|
3
|
3
|
2
|
18
|
0,792
|
|
4
|
2
|
2
|
3
|
2
|
3
|
10
|
0,182
|
|
5
|
3
|
3
|
2
|
3
|
2
|
10
|
0,256
|
|
6
|
1
|
2
|
1
|
3
|
2
|
8
|
0,424
|
|
7
|
2
|
1
|
3
|
4
|
2
|
7
|
0,272
|
|
8
|
3
|
4
|
3
|
4
|
3
|
3
|
0,094
|
|
9
|
2
|
2
|
3
|
3
|
2
|
2
|
0,356
|
|
10
|
4
|
1
|
3
|
1
|
4
|
2
|
0,090
|
|
11
|
1
|
2
|
2
|
2
|
3
|
1
|
0,076
|
Äë˙ ęŕćäîăî íŕáëţäĺíč˙ âűáîđęč đŕńń÷čňűâŕĺňń˙ çíŕ÷ĺíčĺ ęđčňĺđč˙ 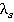 . Ŕëăîđčňě đŕń÷ĺňŕ ęđčňĺđč˙ đŕńńěîňđčě íŕ ďđčěĺđĺ íŕáëţäĺíč˙ . Ŕëăîđčňě đŕń÷ĺňŕ ęđčňĺđč˙ đŕńńěîňđčě íŕ ďđčěĺđĺ íŕáëţäĺíč˙  , ęîňîđîĺ ńňîčň ďîńëĺäíčě â ňŕáëčöĺ óíčęŕëüíűő çíŕ÷ĺíčé (ńňđîęŕ íîěĺđ 11). Äë˙ ďđčěĺđŕ, áűëî âűáđŕíî íŕáëţäĺíčĺ, ęîňîđîĺ íŕčáîëĺĺ ęîíňđŕńňčđóĺň ńî âńĺěč îńňŕëüíűěč. Äë˙ îďđĺäĺëĺííîńňč âűäĺëĺííîĺ íŕáëţäĺíčĺ áóäĺě íŕçűâŕňü ęîíňđîëüíűě. Äë˙ îáîçíŕ÷ĺíč˙ ňŕęîăî íŕáëţäĺíč˙ áóäĺě čńďîëüçîâŕňü ŕááđĺâčŕňóđó ĘÍ (ęîíňđîëüíîĺ íŕáëţäĺíčĺ). Âńţ îńňŕâřóţń˙ âűáîđęó, çŕ čńęëţ÷ĺíčĺě ęîíňđîëüíîăî íŕáëţäĺíč˙, íŕçîâĺě îáó÷ŕţůĺé âűáîđęîé (ÎÂ). , ęîňîđîĺ ńňîčň ďîńëĺäíčě â ňŕáëčöĺ óíčęŕëüíűő çíŕ÷ĺíčé (ńňđîęŕ íîěĺđ 11). Äë˙ ďđčěĺđŕ, áűëî âűáđŕíî íŕáëţäĺíčĺ, ęîňîđîĺ íŕčáîëĺĺ ęîíňđŕńňčđóĺň ńî âńĺěč îńňŕëüíűěč. Äë˙ îďđĺäĺëĺííîńňč âűäĺëĺííîĺ íŕáëţäĺíčĺ áóäĺě íŕçűâŕňü ęîíňđîëüíűě. Äë˙ îáîçíŕ÷ĺíč˙ ňŕęîăî íŕáëţäĺíč˙ áóäĺě čńďîëüçîâŕňü ŕááđĺâčŕňóđó ĘÍ (ęîíňđîëüíîĺ íŕáëţäĺíčĺ). Âńţ îńňŕâřóţń˙ âűáîđęó, çŕ čńęëţ÷ĺíčĺě ęîíňđîëüíîăî íŕáëţäĺíč˙, íŕçîâĺě îáó÷ŕţůĺé âűáîđęîé (ÎÂ).
Ďî äŕííűě ďîëíîé ěíîăîěĺđíîé âűáîđęč đŕńń÷čňűâŕţňń˙ ÷ŕńňîňíűĺ đ˙äű ďî ęŕćäîěó ďđčçíŕęó. Ăđŕôčęč ÷ŕńňîňíűő đ˙äîâ ďđĺäńňŕâëĺíű íŕ đčń. 1. Äë˙ îäíîěĺđíűő đ˙äîâ đĺŕëüíűő âűáîđîę, ęŕę č â ďđčěĺđĺ, őŕđŕęňĺđíî íŕëč÷čĺ íĺęîňîđîăî çíŕ÷ĺíč˙ ń íŕčáîëüřĺé ÷ŕńňîňîé.
Íŕ ďđŕęňčęĺ ÷ŕńňîňŕ ńî÷ĺňŕíč˙ çíŕ÷ĺíčé ďŕđ ďđčçíŕęîâ ňîćĺ ďîä÷čí˙ĺňń˙ íĺęîňîđîé ńňŕňčńňč÷ĺńęîé çŕâčńčěîńňč.  đŕńńěŕňđčâŕĺěîě ęđčňĺđčč ó÷čňűâŕĺňń˙ ńâ˙çü ěĺćäó âńĺěč ďŕđŕěč ďđčçíŕęîâ.
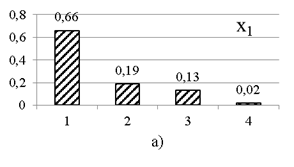 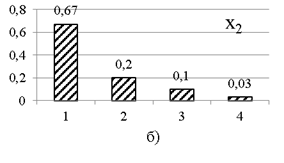
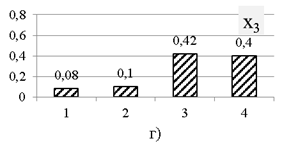 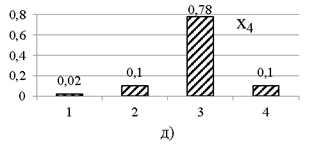
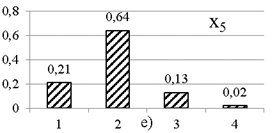
Đčń. 1. ×ŕńňîňíűĺ đ˙äű ďî ď˙ňč ďđčçíŕęŕě âűáîđęč ěîäĺëüíűő äŕííűő
Đŕńńěîňđčě ěíîćĺńňâî âîçěîćíűő ńî÷ĺňŕíčé ďŕđ ďđčçíŕęîâ âűáîđęč čç 5-ňč ďđčçíŕęîâ. Ńî÷ĺňŕíč˙ âîçěîćíűő ďŕđ ďđčçíŕęîâ âűáîđęč ěîćĺň áűňü ďđĺäńňŕâëĺíî ďîëíűě ăđŕôîě G ń ęîëč÷ĺńňâîě đĺáĺđ đŕâíűě d, đŕńń÷čňűâŕĺěűě ďî ôîđěóëĺ(1). Äë˙ 5-ňč ďđčçíŕęîâ d=10.
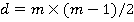 (1) (1)
Đŕń÷ĺň ýëĺěĺíňîâ ęđčňĺđč˙ äë˙ ęîíňđîëüíîăî íŕáëţäĺíč˙ 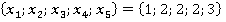 ďđĺäńňŕâëĺí â ňŕáëčöĺ 2. Âňîđîé ńňîëáĺö ňŕáëčöű ńîäĺđćčň âńĺ âîçěîćíűĺ ďŕđű ďđčçíŕęîâ. Ňŕęčĺ ćĺ ńî÷ĺňŕíč˙ ďŕđ áóäóň č äë˙ ëţáîăî äđóăîăî íŕáëţäĺíč˙ âűáîđęč. ďđĺäńňŕâëĺí â ňŕáëčöĺ 2. Âňîđîé ńňîëáĺö ňŕáëčöű ńîäĺđćčň âńĺ âîçěîćíűĺ ďŕđű ďđčçíŕęîâ. Ňŕęčĺ ćĺ ńî÷ĺňŕíč˙ ďŕđ áóäóň č äë˙ ëţáîăî äđóăîăî íŕáëţäĺíč˙ âűáîđęč.
 ňđĺňüĺě ńňîëáöĺ ňŕáëčöű 2 óęŕçŕíű ęîíęđĺňíűĺ çíŕ÷ĺíč˙ ďđčçíŕęîâ äë˙ đŕńńěŕňđčâŕĺěîăî ęîíňđîëüíîăî íŕáëţäĺíč˙. Äŕëĺĺ đŕńń÷čňűâŕĺňń˙ ęîëč÷ĺńňâî ňŕęčő ďŕđ â îáó÷ŕţůĺé âűáîđęĺ áĺç ó÷ĺňŕ ęđŕňíîńňč (÷ĺňâĺđňűé ńňîëáĺö). Íŕďđčěĺđ, ďŕđŕ 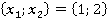 âńňđĺ÷ŕëŕńü ňîëüęî îäíŕćäű â óíčęŕëüíîě íŕáëţäĺíčč ďîä íîěĺđîě 6 â ňŕáëčöĺ 1: âńňđĺ÷ŕëŕńü ňîëüęî îäíŕćäű â óíčęŕëüíîě íŕáëţäĺíčč ďîä íîěĺđîě 6 â ňŕáëčöĺ 1: 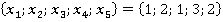 . Ňŕęŕ˙ ďŕđŕ ěîćĺň âńňđĺ÷ŕňüń˙ č â äđóăčő óíčęŕëüíűő íŕáëţäĺíč˙ő (ěŕęńčěóě âî âńĺő, ÷ňî ęđŕéíĺ ěŕëîâĺđî˙ňíî). . Ňŕęŕ˙ ďŕđŕ ěîćĺň âńňđĺ÷ŕňüń˙ č â äđóăčő óíčęŕëüíűő íŕáëţäĺíč˙ő (ěŕęńčěóě âî âńĺő, ÷ňî ęđŕéíĺ ěŕëîâĺđî˙ňíî).
Ňŕáëčöŕ 2. Đŕń÷ĺň ęđčňĺđč˙ äë˙ íŕáëţäĺíč˙ 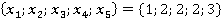
|
Ďŕđŕ
|
Çíŕ÷ĺíč˙
ďđčçíŕęîâ
â ĘÍ
|
Ęîëč÷ĺńňâî
ďŕđ â ÎÂ
áĺç ó÷ĺňŕ ęđŕňíîńňč
|
Ęđŕňíîńňü ďî ÎÂ
|
Ęîëč÷ĺńňâî ďŕđ â ÎÂ
ń ó÷ĺňîě ęđŕňíîńňč
|
×ŕńňîňŕ
ďŕđű
â ÎÂ
|
Âĺń
ďŕđű
|
Âęëŕä ďŕđű
|
|
1
|
2
|
…
|
10
|
|
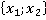
|
{1;2}
|
1
|
8
|
|
|
|
8
|
0,08
|
0,2
|
0,016
|
|
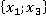
|
{1;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
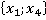
|
{1;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
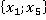
|
{1;3}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
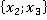
|
{2;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
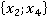
|
{2;2}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
|
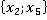
|
{2;3}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
|
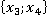
|
{2;2}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
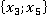
|
{2;3}
|
0
|
|
|
|
|
0
|
0,00
|
0,2
|
0,000
|
|
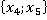
|
{2;3}
|
1
|
10
|
|
|
|
10
|
0,10
|
0,2
|
0,020
|
Äë˙ ďŕđ îáó÷ŕţůĺé âűáîđęč, ăäĺ âńňđĺ÷ŕĺňń˙ đŕńńěŕňđčâŕĺěŕ˙ ďŕđŕ çíŕ÷ĺíčé ęîíňđîëüíîăî íŕáëţäĺíč˙ îňâîä˙ňń˙ íĺńęîëüęî ńňîëáöîâ ňŕáëčöű, îáúĺäčíĺííűő ďîä îáůčě íŕçâŕíčĺě «Ęđŕňíîńňü λ. Ńëĺäóţůčé ńňîëáĺö ńîäĺđćčň ńóěěó âńňđĺ÷ŕĺěîńňč ďŕđű âî âńĺé îáó÷ŕţůĺé âűáîđęĺ. ×ŕńňîňŕ ďŕđű đŕńń÷čňűâŕĺňń˙ ďóňĺě íîđěčđîâŕíč˙ âńňđĺ÷ŕĺěîńňč ďî îáúĺěó îáó÷ŕţůĺé âűáîđęč (â íŕřĺě ńëó÷ŕĺ n=100).
Äë˙ đŕńńěŕňđčâŕĺěîăî ęîíňđîëüíîăî íŕáëţäĺíč˙ îáíŕđóćĺíî ňîëüęî ďî îäíîěó ńîâďŕäĺíčţ ďŕđ â ÷ĺňűđĺő ńëó÷ŕ˙ő (÷ĺňűđĺ ĺäčíčöű â ńňîëáöĺ «Ęîëč÷ĺńňâî ďŕđ â Πáĺç ó÷ĺňŕ ęđŕňíîńňč» â ňŕáëčöĺ 2). Ęŕćäîĺ óíčęŕëüíîĺ çíŕ÷ĺíčĺ čěĺĺň ńâîţ ęđŕňíîńňü Qs. Íŕďđčěĺđ, íŕáëţäĺíčĺ ďîä íîěĺđîě 6 â Πčěĺĺň ęđŕňíîńňü 8, ŕ äđóăîĺ íŕáëţäĺíčĺ 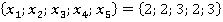 ďîä íîěĺđîě 4, čěĺţůĺĺ ŕíŕëîăč÷íóţ ďŕđó ďîä íîěĺđîě 4, čěĺţůĺĺ ŕíŕëîăč÷íóţ ďŕđó 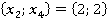 â ęîíňđîëüíîé âűáîđęĺ čěĺĺň ęđŕňíîńňü 10. Ńóěěŕđíŕ˙ ęđŕňíîńňü ďîâňîđĺíč˙ ńîâďŕäĺíčé ęŕćäîé ďŕđű çíŕ÷ĺíčé îáó÷ŕţůĺé âűáîđęč č ęîíňđîëüíîăî íŕáëţäĺíč˙ çŕďčńŕíŕ â ńňîëáöĺ «Ęîëč÷ĺńňâî ďŕđ â Πń ó÷ĺňîě ęđŕňíîńňč» ňŕáëčöű 2. â ęîíňđîëüíîé âűáîđęĺ čěĺĺň ęđŕňíîńňü 10. Ńóěěŕđíŕ˙ ęđŕňíîńňü ďîâňîđĺíč˙ ńîâďŕäĺíčé ęŕćäîé ďŕđű çíŕ÷ĺíčé îáó÷ŕţůĺé âűáîđęč č ęîíňđîëüíîăî íŕáëţäĺíč˙ çŕďčńŕíŕ â ńňîëáöĺ «Ęîëč÷ĺńňâî ďŕđ â Πń ó÷ĺňîě ęđŕňíîńňč» ňŕáëčöű 2.
Äŕëĺĺ đŕńń÷čňűâŕĺňń˙ ÷ŕńňîňŕ âńňđĺ÷ŕĺěîńňč ęŕćäîé ďŕđű îáó÷ŕţůĺé âűáîđęč â ęîíňđîëüíîě íŕáëţäĺíčč (ńňîëáĺö «×ŕńňîňŕ» â ňŕáëčöĺ 2). Äë˙ ýňîăî «Ęîëč÷ĺńňâî ďŕđ â Πń ó÷ĺňîě ęđŕňíîńňč» äĺëčňń˙ íŕ îáúĺě îáó÷ŕţůĺé âűáîđęč (â íŕřĺě ńëó÷ŕĺ 100).
Îäíŕęî â îáůĺě ńëó÷ŕĺ âńĺ ďŕđű íĺđŕâíîçíŕ÷íű. Ęîëč÷ĺńňâî âîçěîćíűő âŕđčŕíňîâ îňâĺňîâ çŕâčńčň îň ęîëč÷ĺńňâŕ çíŕ÷ĺíčé ďđčçíŕęîâ, ńîńňŕâë˙ţůčő ďŕđó (â íŕřĺě ńëó÷ŕĺ äë˙ âńĺő ďđčçíŕęîâ 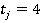 ). Ęîëč÷ĺńňâî âîçěîćíűő âŕđčŕíňîâ çíŕ÷ĺíčé ęŕćäîé ďŕđű ďđčçíŕęîâ ). Ęîëč÷ĺńňâî âîçěîćíűő âŕđčŕíňîâ çíŕ÷ĺíčé ęŕćäîé ďŕđű ďđčçíŕęîâ 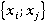 đŕâíî đŕâíî 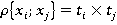 (â íŕřĺě ńëó÷ŕĺ âńĺ äë˙ âńĺő ďŕđ ďđčçíŕęîâ (â íŕřĺě ńëó÷ŕĺ âńĺ äë˙ âńĺő ďŕđ ďđčçíŕęîâ 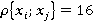 ). Ďîýňîěó äë˙ đŕçëč÷íűő ďŕđ íĺîáőîäčěî ââĺńňč ďîďđŕâî÷íűé ęîýôôčöčĺíň (âĺń ďŕđű). Âĺńŕ äë˙ đŕçíűő ńî÷ĺňŕíčé ďŕđ ďđčçíŕęîâ â îáůĺě ńëó÷ŕĺ đŕńń÷čňűâŕţňń˙ ďî ôîđěóëĺ (2): ). Ďîýňîěó äë˙ đŕçëč÷íűő ďŕđ íĺîáőîäčěî ââĺńňč ďîďđŕâî÷íűé ęîýôôčöčĺíň (âĺń ďŕđű). Âĺńŕ äë˙ đŕçíűő ńî÷ĺňŕíčé ďŕđ ďđčçíŕęîâ â îáůĺě ńëó÷ŕĺ đŕńń÷čňűâŕţňń˙ ďî ôîđěóëĺ (2):
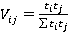 (2) (2)
 íŕřĺě ďđčěĺđĺ âńĺ ďŕđű áóäóň čěĺňü îäčí č ňîň ćĺ âĺń 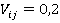 . Çŕňĺě đŕńń÷čňűâŕĺňń˙ «âęëŕä ęŕćäîé ďŕđű» ęŕę ďđîčçâĺäĺíčĺ ÷ŕńňîňű ďŕđű íŕ âĺń. Ńóěěčđîâŕíčĺ ďî âęëŕäŕě ęŕćäîé ďŕđű äŕĺň îáůĺĺ çíŕ÷ĺíčĺ ęđčňĺđč˙ . Çŕňĺě đŕńń÷čňűâŕĺňń˙ «âęëŕä ęŕćäîé ďŕđű» ęŕę ďđîčçâĺäĺíčĺ ÷ŕńňîňű ďŕđű íŕ âĺń. Ńóěěčđîâŕíčĺ ďî âęëŕäŕě ęŕćäîé ďŕđű äŕĺň îáůĺĺ çíŕ÷ĺíčĺ ęđčňĺđč˙ 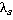 .  äŕííîě ńëó÷ŕĺ äë˙ ęîíňđîëüíîăî íŕáëţäĺíč˙ çíŕ÷ĺíčĺ ęđčňĺđč˙ đŕâíî .  äŕííîě ńëó÷ŕĺ äë˙ ęîíňđîëüíîăî íŕáëţäĺíč˙ çíŕ÷ĺíčĺ ęđčňĺđč˙ đŕâíî 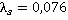 . Íŕ đčń. 2 ďđĺäńňŕâëĺí ăđŕôčę óďîđ˙äî÷ĺííűő çíŕ÷ĺíčé ęđčňĺđč˙ äë˙ âńĺő óíčęŕëüíűő íŕáëţäĺíčé âűáîđęč. . Íŕ đčń. 2 ďđĺäńňŕâëĺí ăđŕôčę óďîđ˙äî÷ĺííűő çíŕ÷ĺíčé ęđčňĺđč˙ äë˙ âńĺő óíčęŕëüíűő íŕáëţäĺíčé âűáîđęč.
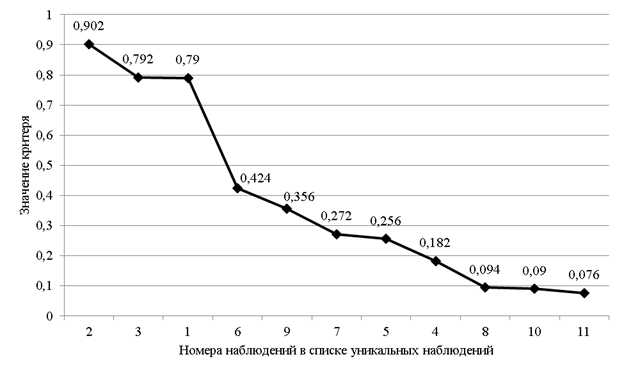
Đčń. 2. Ăđŕôčę çíŕ÷ĺíčé ęđčňĺđč˙ äë˙ óíčęŕëüíűő íŕáëţäĺíčé čç ňŕáëčöű 1
Íŕ ăîđčçîíňŕëüíîé îńč óęŕçŕíű íîěĺđŕ óíčęŕëüíűő íŕáëţäĺíčé. Čç ăđŕôčęŕ âčäíî, ÷ňî ňđč íŕáëţäĺíč˙ âűáčâŕţňń˙ čç îáůĺăî đ˙äŕ íŕáëţäĺíčé âűáîđęč, ďîýňîěó čő ěîćíî đŕńńěŕňđčâŕňü ęŕę «ńîěíčňĺëüíűĺ», ń ňî÷ęč çđĺíč˙ äîńňîâĺđíîńňč äŕííűő.  đĺŕëüíîé ńčňóŕöčč ňŕęčĺ íŕáëţäĺíč˙ íĺîáőîäčěî ďîäâĺđăíóňü ńîäĺđćŕňĺëüíîěó ŕíŕëčçó îňâĺňîâ đĺńďîíäĺíňîâ äë˙ âű˙ńíĺíč˙ ďđč÷čí, â đĺçóëüňŕňĺ ęîňîđűő ŕëăîđčňěîě áűëč âűäĺëĺíű čěĺííî ýňč íŕáëţäĺíč˙. Ďîńęîëüęó «ďîäîçđčňĺëüíűő» ŕíęĺň, ęŕę ďđŕâčëî, íĺ ňŕę ěíîăî, ňî ňŕęîé ŕíŕëčç îáű÷íî íĺ âűçűâŕĺň îńîáűő çŕňđóäíĺíčé. Áëîę-ńőĺěŕ ŕëăîđčňěŕ ďđĺäńňŕâëĺíŕ íŕ đčń.3.
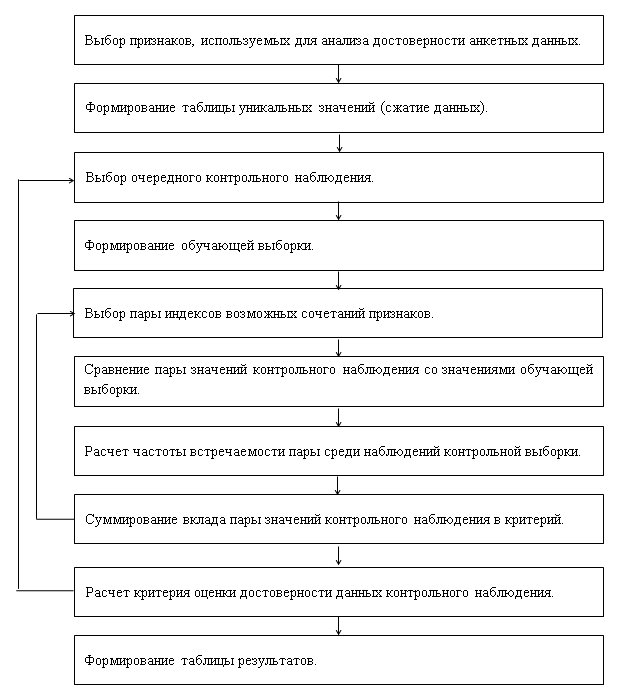
Đčń. 3. Áëîę-ńőĺěŕ ŕëăîđčňěŕ îöĺíęč äîńňîâĺđíîńňč íŕáëţäĺíčé ŕíęĺňíűő äŕííűő
Íŕ îńíîâĺ ďđĺäëîćĺííîăî ěĺňîäŕ ŕíŕëčçŕ äîńňîâĺđíîńňč ŕíęĺňíűő äŕííűő áűëŕ đŕçđŕáîňŕíŕ ęîěďüţňĺđíŕ˙ ďđîăđŕěěŕ â ńđĺäĺ EXCEL. Ęđîěĺ ěîäĺëüíűő äŕííűő, ďđîăđŕěěŕ áűëŕ ďđîňĺńňčđîâŕíŕ č íŕ đĺŕëüíűő äŕííűő č ďîęŕçŕëŕ őîđîřčĺ đĺçóëüňŕňű.
Çŕęëţ÷ĺíčĺ
Îńíîâíűě äîńňîčíńňâîě ďđĺäëîćĺííîăî ěĺňîäŕ ˙âë˙ĺňń˙ ňî, ÷ňî îí ďîçâîë˙ĺň îďĺđŕňčâíî ŕíŕëčçčđîâŕňü ěíîăîěĺđíűĺ âűáîđęč ňŕáëčö äŕííűő, ńôîđěčđîâŕííűő íŕ îńíîâĺ îíëŕéí-îďđîńîâ. Ěĺňîä î÷ĺíü ďđîńň â čńďîëüçîâŕíčč č äîńňóďĺí äŕćĺ äë˙ íĺ čńęóřĺííűő čńńëĺäîâŕňĺëĺé.
Ďđĺčěóůĺńňâî ěĺňîäŕ ńîńňîčň â ňîě, ÷ňî ďîçâîë˙ĺň ó÷ĺńňü ëŕňĺíňíűĺ ńâ˙çč, ďđčńóůčĺ čńńëĺäóĺěîěó îáúĺęňó. Ďđč íĺäîáđîńîâĺńňíîě îňíîřĺíčč ę îďđîńó ÷ŕńňč đĺńďîíäĺíňîâ îíč íĺ çŕäóěűâŕţňń˙ î âîçěîćíűő ńňŕňčńňč÷ĺńęčő ńâ˙ç˙ő č ňĺě ńŕěűě ďîđîćäŕţň äŕííűĺ, âűďŕäŕţůčĺ čç îáůĺăî đ˙äŕ íŕáëţäĺíčé. Ĺńëč áű ňŕęčĺ đĺńďîíäĺíňű ďîďűňŕëčńü ďđĺäďđčí˙ňü ďîďűňęó óěűřëĺííîé ôŕëüńčôčęŕöčč îňâĺňîâ, ňî íŕ çŕďîëíĺíčĺ ňŕęîé ŕíęĺňű ďîňđĺáîâŕëîńü áű çŕňđŕňčňü âđĺěĺíč áîëüřĺ, ÷ĺě íŕ ďđĺäîńňŕâëĺíčĺ îáúĺęňčâíîé číôîđěŕöčč.
Äë˙ ŕíŕëčçŕ äîńňîâĺđíîńňč äŕííűő îíëŕéí-îďđîńîâ öĺëĺńîîáđŕçíî čńďîëüçîâŕňü đ˙ä ęđčňĺđčĺâ. Íŕďđčěĺđ, ěîćíî čńďîëüçîâŕňü ęđčňĺđčč, ęîňîđűĺ áűëč đŕçđŕáîňŕíű ŕâňîđîě đŕíĺĺ äë˙ đŕçëč÷íűő ňčďîâ äŕííűő [20].
Âîçěîćíî, ďđĺäëîćĺííűé ěĺňîä â äŕëüíĺéřĺě ěîćĺň áűňü čńďîëüçîâŕí äë˙ ęëŕńńčôčęŕöčč íŕáëţäĺíčé. Íŕďđčěĺđ, â ăđŕôčęĺ íŕ đčń. 3 ěîćíî âűäĺëčňü ňđč çîíű, ęîňîđűĺ ěîăóň áűňü ďîëîćĺíű â îńíîâó ęëŕńńčôčęŕöčč. Ýňŕ âîçěîćíîńňü ěîćĺň áűňü îďđĺäĺëĺíŕ â đĺçóëüňŕňĺ äŕëüíĺéřčő čńńëĺäîâŕíčé.
References
1. Dolgorukov A.M. Internet i budushchee sotsiologii // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2015. – ą 2 (125). – S. 32-43.
2. Belikova Yu.V. Sravnitel'nyi analiz servisov dlya provedeniya onlain oprosov // Aktual'nye nauchnye issledovaniya v sovremennom mire. – 2016. – ą 5–4 (13). – S. 36–41.
3. Efimova D.M., Ermolaev S.V. Sravnitel'nyi analiz servisov dlya prodvizheniya oprosa v seti internet // Vestnik Rossiiskogo ekonomicheskogo universiteta im. G.V. Plekhanova. Vstuplenie. Put' v nauku. – 2014. – ą 1-2 (9). – S. 88-95.
4. Nasretdinova M.M. Aktual'nost' onlain issledovanii v Rossii // Psikhologiya, sotsiologiya i pedagogika. – 2014. – ą 6 (33). – S. 24.
5. Nekrasov S.I. Sravnenie rezul'tatov onlain-i offlain-oprosov (na primere anket raznoi slozhnosti) // Sotsiologiya: metodologiya, metody, matematicheskoe modelirovanie. – 2011. – ą 32. – S. 53-74.
6. Farakhutdinov Sh.F. Professional'nye respondenty kamen' predknoveniya onlain-oprosov v sovremennoi Rossii // Teleskop: zhurnal sotsiologicheskikh i marketingovykh issledovanii. – 2011. – ą 2. – S. 45-47.
7. Shkurin D.V. Sravnitel'naya otsenka kachestva dannykh oflain i onlain-oprosov // Diskussiya. – 2015. – ą
8. – S. 101–105. 8. Alessi E. J., Martin J. I. Conducting an internet-based survey: Benefits, pitfalls, and lessons learned // Social Work Research. – 2010. – Vol. 34. – N 2. – P. 122–128.
9. Hunter L. Challenging the reported disadvantages of e-questionnaires and addressing methodological issues of online data collection // Nurse researcher. – 2012. – Vol. 20. – N 1. – P. 11–20.
10. McPeake J., Bateson M., O’Neill A. Electronic surveys: how to maximise success // Nurse researcher. – 2014. – Vol. 21. – N 3. – P. 24–26.
11. Phillips K. Data Use: An evaluation of quality-control questions // Quirk’s Marketing Research Review. December. 2013. [Elektronnyi resurs]. Rezhim dostupa: http://www.quirks.com/articles/2013/20131205.aspx (data obrashcheniya 17 dekabrya 2018).
12. Zaveri A. et al. Quality assessment for linked data: A survey // Semantic Web. – 2016. – Vol. 7. – ą. 1. – P. 63-93.
13. Galitskii E.B., Mal'tseva P.V. Potentsial'nye istochniki oshibok v dannykh onlain-oprosov // Prakticheskii marketing. – 2013. – ą 10 (200). – S. 2-8.
14. Mavletova A.M., Maloshonok N.G., Terent'ev E.A. Vliyanie elementov priglasheniya na uvelichenie doli otklikov v onlain-oprosakh // Sotsiologiya: metodologiya, metody, matematicheskoe modelirovanie. – 2014. – ą 38. – S. 72-95.
15. Maloshonok N.G., Terent'ev E.A. Vliyanie dizaina na kachestvo dannykh v onlain-oprosakh studentov // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2014. – ą 6 (124). – S. 15-27.
16. Moiseev S.P., Savinkova Yu.K. Vyborka, napravlyaemaya respondentom, v onlain-oprose: k voprosu o dinamike i kachestve // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2014. – ą 6 (124). – S. 43-50.
17. Fedorovskii A.M. Kachestvo onlain-oprosov. Metody proverok // Monitoring obshchestvennogo mneniya: ekonomicheskie i sotsial'nye peremeny. – 2015. – ą 3 (127). – S. 28-35.
18. Martyshenko S.N. Metodicheskoe obespechenie analiza dannykh monitoringa sotsial'no-ekonomicheskikh protsessov v munitsipal'nykh obrazovaniyakh // Ekonomika i menedzhment sistem upravleniya. – 2012. – T. 6. – ą 4-2. – S. 259-267.
19. Martyshenko S.N., Martyshenko N.S. Metody obrabotki nechislovykh dannykh v sotsial'no-ekonomicheskikh issledovaniyakh // Vestnik Tikhookeanskogo gosudarstvennogo ekonomicheskogo universiteta. – 2006. – ą 4 (40). – S. 48-57.
20. Martyshenko S.N., Martyshenko N.S. Sovremennye metody obrabotki marketingovoi informatsii : monografiya. – Vladivostok: Izdatel'stvo VGUES, 2014. – 148 s.
|








