|
DOI: 10.7256/2585-7797.2018.1.25686
Received:
11-03-2018
Published:
21-04-2018
Abstract:
The article addresses the issue of transcribing handwritten materials of the 1950 Norwegian Population Census. These are 801 000 scanned double sided questionnaires. Optical character recognition programs have been improving for over four decades. Now researchers aim to extend similar techniques to handle handwritten historical source material. The article analyzes studies carried by the Center of Historical Documents at the University of Tromsø which address handwritten text recognition as well as considers the use of various text recognition techniques as far as nominative sources are concerned. Since it is difficult to distinguish and separate individual handwritten characters, the words are mathematically clustered according to image similarity or searched for within sources that have been transcribed earlier. After the recognition quality control, the software uses the line numbers to place the information taken from the transcribed cells. After that the latter become a part of the census database. Moreover, special software has been developed to process handwritten numerical codes, data on occupations and education, etc. The methods offered in the article provide for handwritten texts transcribing quality improvement and can be used to recognize nominative source notes in Russia, for instance, parish registers and vital records. The main goals are still the search for methods and algorithms which optimally link different variables as well as the rationalization of interactive proofread methods.
Keywords:
databases, Norwegian population census, record linkage, transcription, OCR, Deep learning, neural network, Historical Population Register, graphical user interface, hand writing
Ňđŕíńęđčáčđîâŕíčĺ čńňîđč÷ĺńęčő äŕííűő, ďđîâîäčěîĺ â Íîđâĺćńęîě öĺíňđe čńňîđč÷ĺńęîé äîęóěĺíňŕöčč Óíčâĺđńčňĺňŕ Ňđîěńî, ń ńŕěîăî íŕ÷ŕëŕ áűëî ňĺńíî ńâ˙çŕíî ń ęîěďüţňĺđíűěč ěĺňîäŕěč îďňč÷ĺńęîăî ń÷čňűâŕíč˙ číôîđěŕöčč c áóěŕćíűő íîńčňĺëĺé. Ďđč ýňîě, ďĺđâîíŕ÷ŕëüíî číôîđěŕöč˙ ââîäčëŕńü íĺ ÷ĺđĺç öĺíňđŕëčçîâŕííűĺ ęîěďüţňĺđíűĺ ňĺđěčíŕëű ęđóďíűő čńńëĺäîâŕňĺëüńęčő öĺíňđîâ, ŕ ńčëŕěč ěŕřčíčńňîę, íŕáčđŕâřčő ňĺęńň čńňîđč÷ĺńęčő äîęóěĺíňîâ íŕ îáű÷íűő ďĺ÷ŕňíűő ěŕřčíęŕő. Óíčâĺđńčňĺňńęčé ńęŕíĺđ Kurzweil OCR, ďđčîáđĺňĺííűé â 1978 ăîäó, ěîă ń÷čňűâŕňü ňîëüęî řđčôň ďčřóůčő ěŕřčíîę — OCR-B.
Ń íŕ÷ŕëŕ 1980-ő ăîäîâ ěű ńňŕëč čńďîëüçîâŕňü ęîěďüţňĺđű äë˙ îďňč÷ĺńęîăî đŕńďîçíŕâŕíč˙ ěŕřčíîďčńíűő ňĺęńňîâ. Čěĺâřĺĺń˙ â íŕřĺě đŕńďîđ˙ćĺíčč ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ, óâű, äŕâŕëî âîçěîćíîńňü đŕńďîçíŕňü ňîëüęî řđčôňű č ňĺęńňű îďđĺäĺëĺííîăî ňčďŕ. Čńďîëüçîâŕíčĺ ęîěďüţňĺđŕ â đŕáîňĺ ńî ńďčńęŕěč íîđâĺćńęčő ôĺđěĺđîâ, ńîńňŕâëĺííűő â 1886 ă. â ôîđěĺ ńëîćíűő ňŕáëčö, ńňŕëî âîçěîćíî áëŕăîäŕđ˙ ďđîăđŕěěíîěó îáĺńďĺ÷ĺíčţ, ńďĺöčŕëüíî đŕçđŕáîňŕííîěó đîńńčéńęčěč IT-ńďĺöčŕëčńňŕěč. Ěĺňîä áűë îďčńŕí â îäíîě čç âűďóńęîâ ćóđíŕëŕ «History and Computing»[1].
Ńîâđĺěĺííîĺ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ đŕńďîçíŕĺň ďĺ÷ŕňíűé ňĺęńň ęëŕńńč÷ĺńęčě ëŕňčíńęčě řđčôňîě, îäíŕęî îíî ďî-ďđĺćíĺěó íĺ ńďđŕâë˙ĺňń˙ ń ăîňč÷ĺńęčěč řđčôňŕěč č ňĺęńňŕěč íŕ íŕöčîíŕëüíűő ˙çűęŕő, ŕëôŕâčňű ęîňîđűő ńîäĺđćŕň ńďĺöčôč÷ĺńęčĺ ńčěâîëű. Ďđîáëĺěîé ˙âë˙ĺňń˙ ňŕęćĺ îňńóňńňâčĺ ńňŕíäŕđňíűő ďđîáĺëîâ ěĺćäó ńëîâŕěč, ěĺëęčĺ ăđŕôű, đŕçäĺëčňĺëüíűĺ âĺđňčęŕëüíűĺ ëčíčč č ň.ä., ęîňîđűĺ íĺ äŕţň âîçěîćíîńňč ěŕřčíĺ ęîđđĺęňíî đŕńďîçíŕňü číôîđěŕöčţ.
 ňî âđĺě˙ ęŕę ňĺőíčęŕ îďňč÷ĺńęîăî đŕńďîçíŕâŕíč˙ ďĺ÷ŕňíűő ńčěâîëîâ äčíŕěč÷íî đŕçâčâŕĺňń˙, đŕńďîçíŕâŕíčĺ đóęîďčńíîăî ňĺęńňŕ âńĺ ĺůĺ ěŕëîíŕäĺćíî č ňđĺáóĺň đŕçđŕáîňęč îńîáîăî ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙. Ăäĺ-ňî ďîńĺđĺäčíĺ ěĺćäó ýňčěč ďîëţńŕěč íŕőîäčňń˙ âŕđčŕíň đŕńďîçíŕâŕíč˙ çŕďčńĺé â îďđîńíűő ëčńňŕő, ęîňîđűĺ čńďîëüçîâŕëčńü â ŃŘŔ: âđó÷íóţ, íî ďĺ÷ŕňíűěč áóęâŕěč, ăäĺ ęŕćäŕ˙ áóęâŕ âďčńűâŕëŕńü â îňäĺëüíóţ ęëĺňęó [2]. Ŕíŕëîăč÷íűé ďđčĺě ďđčěĺí˙ëń˙ ďđč çŕďîëíĺíčč číäčâčäóŕëüíűő đĺăčńňđŕöčîííűő ëčńňîâ âî âđĺě˙ ďđîâĺäĺíč˙ ďĺđĺďčńĺé íŕńĺëĺíč˙ â 1891 č 1920 ăă. â Íîđâĺăčč â, ŕ ňŕęćĺ âî Ôđŕíöčč č Ăĺđěŕíčč. Ďđč ńęŕíčđîâŕíčč ňŕęîăî đîäŕ čńňî÷íčęîâ ęëţ÷ĺâűĺ ńëîâŕ čäĺíňčôčöčđóţňń˙ ń âűńîęîé ńňĺďĺíüţ äîńňîâĺđíîńňč, ęđîěĺ ňîăî, ŕâňîěŕňč÷ĺńęč đŕńďîçíŕţňń˙ íĺęîňîđűĺ öčôđű č ęîäű. ×ňî ęŕńŕĺňń˙ čěĺí, ďđîôĺńńčé č äđóăîé ďĺđńîíŕëüíîé číôîđěŕöčč, ňî ĺĺ íĺâîçěîćíî ń÷čňŕňü ń ďîěîůüţ OCR č ďîäîáíűő ĺé ňĺőíčę, čç-çŕ ńëîćíîńňĺé đŕńďîçíŕâŕíč˙ č đŕçäĺëĺíč˙ íŕ îňäĺëüíűĺ áóęâű ńëîâ đóęîďčńíîăî ňĺęńňŕ. Âěĺńňî ýňîăî öĺëűĺ ńëîâŕ ěŕňĺěŕňč÷ĺńęč ăđóďďčđóţňń˙ â ęëŕńňĺđű â çŕâčńčěîńňč îň ńňĺďĺíč ńőîćĺńňč. Ňŕęčě îáđŕçîě, číôîđěŕöč˙ đ˙äŕ ďîëĺé, íŕďđčěĺđ, ń óęŕçŕíčĺě ěĺńňŕ đîćäĺíč˙, ěîćĺň áűňü đŕńřčôđîâŕíŕ öĺëčęîě, áĺç đŕçáčâęč íŕ îňäĺëüíűĺ áóęâű, ĺńëč âčä ńëîâŕ áóäĺň őîňü íĺěíîăî ńîîňâĺňńňâîâŕňü ęëŕńňĺđíűě îáđŕçöŕě íŕďčńŕíč˙ ýňîăî ńëîâŕ. Ďîńęîëüęó đŕńďîëîćĺíčĺ ďîëĺé ń čäĺíňč÷íîé číôîđěŕöčĺé â ôîđěŕő ďĺđĺďčńĺé ńňŕíäŕđňíî, ýňî ďîçâîë˙ĺň đŕöčîíŕëčçčđîâŕňü ňđŕíńęđčáčđîâŕíčĺ ôîđěóë˙đŕ ęëĺňęŕ çŕ ęëĺňęîé — ńëîâî çŕ ńëîâîě.  ÷ŕńňíîńňč, ňŕęîé ěĺňîä áűë ďđčěĺíĺí ďđč ňđŕíńęđčáčđîâŕíčč çŕďčńĺé áđŕęîâ, çŕęëţ÷ĺííűő â Áŕđńĺëîíĺ â 1451–1905 ăă. [3]. Ŕíŕëîăč÷íűé ďîäőîä čńďîëüçóĺňń˙ â řâĺéöŕđńęîě ďđîĺęňĺ číňĺđŕęňčâíîăî ňđŕíńęđčáčđîâŕíč˙ ňĺęńňîâ Transkribus (https://transkribus.eu/Transkribus/). Đŕńďîëŕăŕ˙ îářčđíűě ěŕńńčâîě îňńęŕíčđîâŕííűő č ňđŕíńęđčáčđîâŕííűő ěŕňĺđčŕëîâ ďĺđĺďčńĺé, ěű ěîćĺě čńďîëüçîâŕňü ýňîň ěĺňîä äë˙ îáó÷ĺíč˙ ěŕřčí ń čńęóńńňâĺííűě číňĺëëĺęňîě, ÷ňî çíŕ÷čňĺëüíî đŕńřčđčň âîçěîćíîńňč â đŕçâčňčč îďňč÷ĺńęîăî đŕńďîçíŕâŕíč˙ đóęîďčńíűő ňĺęńňîâ.
Ďĺđĺďčńü íŕńĺëĺíč˙ 1950 ă.[1]
Ďĺđĺďčńü 1891 ă. óćĺ âűëîćĺíŕ â číňĺđíĺňĺ, ŕ ďĺđĺďčńü 1920 ă. ńňŕíĺň äîńňóďíŕ ÷ĺđĺç äâŕ ăîäŕ, â 2020 ă., â ńîîňâĺňńňâčč ń çŕęîíîě îá îőđŕíĺ ďĺđńîíŕëüíűő äŕííűő. Č ňîăäŕ Íŕöčîíŕëüíűé ŕđőčâ ńěîćĺň îňďđŕâčňü ěŕňĺđčŕëű ďĺđĺďčńč çŕ ăđŕíčöó äë˙ ňđŕíńęđčáčđîâŕíč˙, áîëüřóţ ÷ŕńňü đŕńőîäîâ íŕ ęîňîđîĺ îďëŕň˙ň ęîěěĺđ÷ĺńęčĺ ęîěďŕíčč, ďđĺäîńňŕâë˙ţůčĺ óńëóăč ăĺíĺŕëîăŕě. Ďĺđĺďčńč 1801, 1865, 1875, 1891, 1900 č 1910 ăă. óćĺ đŕńřčôđîâŕíű ňŕęčě ńďîńîáîě č íŕőîä˙ňń˙ â îňęđűňîě äîńňóďĺ.  ňî ćĺ âđĺě˙, áîëüřîé číňĺđĺń ďđĺäńňŕâë˙ţň č áîëĺĺ ďîçäíčĺ ďĺđĺďčńč, č ďđĺćäĺ âńĺăî 1930 č 1910 ăă., ńîäĺđćŕůčĺ ěŕňĺđčŕëű, ęîňîđűő ěîăóň áűňü čńďîëüçîâŕíű, â ÷ŕńňíîńňč, â ěĺäčöčíńęčő čńńëĺäîâŕíč˙ő. Îíč áűëč îňńęŕíčđîâŕíű Íŕöčîíŕëüíűě ŕđőčâîě â đŕěęŕő íŕřĺăî ďđîĺęňŕ ďî ńîçäŕíčţ «Čńňîđč÷ĺńęîăî Đĺĺńňđŕ Íŕńĺëĺíč˙ Íîđâĺăčč» (Historical Population Register for Norway). Äŕííűĺ âńĺő ďîńëĺäóţůčő ďĺđĺďčńĺé Íîđâĺăčč, íŕ÷číŕ˙ ń 1960 ă., âîřëč â đĺńóđń «Öĺíňđŕëüíűé Đĺĺńňđ íŕńĺëĺíč˙ Íîđâĺăčč» (Central Population Register), ęîňîđűé îőâŕňűâŕĺň ďĺđčîä ń 1964 ă. äî íŕńňî˙ůĺăî âđĺěĺíč. Ęđîěĺ ňîăî, â íŕřĺě đŕńďîđ˙ćĺíčč čěĺĺňń˙ «Đĺĺńňđ ďđč÷čí ńěĺđňč» (Causes of Death Register), äŕííűĺ ęîňîđîăî, íŕ÷číŕ˙ ń 1951 ă., ňŕęćĺ çŕíĺńĺíű â ýëĺęňđîííóţ áŕçó äŕííűő. Ďîńëĺ ňđŕíńęđčáčđîâŕíč˙ ěŕňĺđčŕëîâ ďĺđĺďčńč 1950 ă., ńîäĺđćŕůĺé číôîđěŕöčţ î 3,3 ěčëëčîíîâ ëţäĺé, ĺĺ ěîćíî áóäĺň ńâ˙çŕňü ń Đĺĺńňđîě ďđč÷čí ńěĺđňč č čçó÷čňü îáńňî˙ňĺëüńňâŕ č ýęîëîăč÷ĺńęóţ îáńňŕíîâęó âçđîńëĺíč˙ çíŕ÷čňĺëüíűő ăđóďď íŕńĺëĺíč˙ Íîđâĺăčč. Îäíŕęî îńóůĺńňâčňü ňđŕíńęđčáčđîâŕíčĺ ďĺđĺďčńč 1950 ă. áĺç čńďîëüçîâŕíč˙ ęîěěĺđ÷ĺńęčő đĺńóđńîâ ăĺíĺŕëîăč÷ĺńęčő ńňđóęňóđ äîâîëüíî ńëîćíî. Ňîćĺ ęŕńŕĺňń˙ ďĺđĺďčńĺé 1930 č 1946 ăă., ŕ ňŕęćĺ çŕęđűňűő ďîęŕ äë˙ čńńëĺäîâŕňĺëĺé çŕďčńĺé î đîćäĺíč˙ő çŕ 1935–1964 ăă. č ďĺđĺďčńč 1946 ă.  ďĺđčîä âňîđîé ěčđîâîé âîéíű â Íîđâĺăčč, ęŕę č âî ěíîăčő äđóăčő ńňđŕíŕő, ďĺđĺďčńĺé íĺ ďđîâîäčëîńü [4].
Ěŕňĺđčŕëű ďĺđĺďčńč 1950 ăîäŕ ďđĺäńňŕâë˙ţň ńîáîé 801 ňűń˙÷ó îďđîńíűő ëčńňîâ — ôîđěóë˙đîâ đŕçěĺđîě 29.7x70.7 ńě, çŕďîëíĺííűő âđó÷íóţ ń îáĺčő ńňîđîí. Îíč áűëč îňńęŕíčđîâŕíű, â đĺçóëüňŕňĺ ÷ĺăî áűëč ďîëó÷ĺíű áîëĺĺ ÷ĺě 1,6 ěčëëčîíŕ čçîáđŕćĺíčé â ôîđěŕňŕő jpeg č jpeg2000 — â ńćŕňîě č ďîëíîě đŕçđĺřĺíčč ńîîňâĺňńňâĺííî.  ęŕćäîě ôîđěóë˙đĺ ěîăëî áűňü çŕđĺăčńňđčđîâŕíî äî 10 ÷ĺëîâĺę, č â äîďîëíĺíčĺ ę îáű÷íűě ďĺđĺěĺííűě ďĺđĺďčńč â íčő ńîäĺđćčňń˙ číôîđěŕöč˙ îá îáđŕçîâŕíčč, đĺëčăčîçíîé ďđčíŕäëĺćíîńňč č ďđĺäűäóůčő ďĺđĺäâčćĺíč˙ő. Ęđîěĺ ňîăî, â ôîđěóë˙đĺ ďđĺäóńěîňđĺíű ńďĺöčŕëüíűĺ ńňđîęč äë˙ âíĺńĺíč˙ číôîđěŕöčč â çŕęîäčđîâŕííîé ôîđěĺ, â ňîě ÷čńëĺ î ďđîôĺńńčč č äđóăčő ďĺđńîíŕëüíűő őŕđŕęňĺđčńňčęŕő. Îáđŕňíŕ˙ ńňîđîíŕ ôîđěóë˙đŕ ńîäĺđćčň ŕäđĺńíóţ číôîđěŕöčţ, ęŕę ďđŕâčëî, íŕçâŕíčĺ ôĺđěű č íŕëîăîâűé íîěĺđ â ńĺëüńęîé ěĺńňíîńňč čëč íŕçâŕíčĺ óëčöű č íîěĺđŕ äîěŕ â ăîđîäŕő. Ńîáëţäĺíčĺ ńňđîăîé ďîńëĺäîâŕňĺëüíîńňč čçîáđŕćĺíčé ôîđěóë˙đŕ čěĺĺň đĺřŕţůĺĺ çíŕ÷ĺíčĺ äë˙ äŕëüíĺéřĺé đŕáîňű.
Âńĺ čçîáđŕćĺíč˙ áűëč ďđîŕíŕëčçčđîâŕíű ń ďîěîůüţ ďđîăđŕěěű Analyseform, đŕçđŕáîňŕííîé Íîđâĺćńęčě âű÷čńëčňĺëüíűě öĺíňđîě (Norwegian Computing Center) č ďđčěĺíĺííîé Íîđâĺćńęčě Öĺíňđîě čńňîđč÷ĺńęčő äŕííűő (Norwegian Historical Data Centre)[2]. Ýňŕ ďđîăđŕěěŕ čäĺíňčôčöčđóĺň ňčď ôîđěóë˙đŕ č đŕçäĺë˙ĺň ĺăî ďîë˙ íŕ îňäĺëüíűĺ čçîáđŕćĺíč˙, ęîňîđűĺ őđŕí˙ňń˙ â áŕçĺ äŕííűő.  íĺé ęŕćäîĺ čçîáđŕćĺíčĺ ńâ˙çŕíî ń íîěĺđîě ôîđěóë˙đŕ, íîěĺđîě ęîíęđĺňíîé ńňđîęč č ęëĺňęč. Ďđč ýňîě, číôîđěŕöč˙, îęŕçŕâřŕ˙ń˙ çŕ ăđŕíčöĺé ęëĺňęč, îňâĺäĺííîé äë˙ íĺĺ, ěîćĺň áűňü óňđŕ÷ĺíŕ. Ďđîăđŕěěŕ đŕńń÷čňŕíŕ íŕ đŕçäĺëĺíčĺ ôŕěčëčč, ďĺđâîăî č âňîđîăî čěĺíč çŕđĺăčńňđčđîâŕííîăî ÷ĺëîâĺęŕ ďî îňäĺëüíűě čçîáđŕćĺíč˙ě. Îäíŕęî ýňî íĺ óäŕĺňń˙ â ňĺő ńëó÷ŕ˙ő, ęîăäŕ ěĺćäó ôŕěčëčĺé č čěĺíĺě íĺň ďđîáĺëŕ, ďđîáĺë íŕőîäčňń˙ ďîńĺđĺäčíĺ čěĺíč čëč äâŕ čěĺíč íŕďčńŕíű îäíî íŕä äđóăčě. Ďđîăđŕěěŕ ňŕęćĺ đŕńń÷čňŕíŕ íŕ đŕńďîçíŕâŕíčĺ öčôđîâűő ęîäîâ, íî ďëîőî ńďđŕâë˙ĺňń˙ ń äâóő č ňđĺőçíŕ÷íűěč ÷čńëŕěč, č đĺřĺíč˙ ęŕę ĺĺ îáó÷čňü îňäĺë˙ňü îäíó öčôđó îň äđóăîé ďîęŕ íĺ íŕéäĺíî.
Ęŕćäŕ˙ ęëĺňęŕ ń ňĺęńňîě ŕíŕëčçčđóĺňń˙ ń ďîěîůüţ 30 ěŕňĺěŕňč÷ĺńęčő ďĺđĺěĺííűő, ęîňîđűĺ őŕđŕęňĺđčçóţň ňĺęńňîâîĺ čçîáđŕćĺíčĺ. Íŕ îńíîâĺ ýňîé číôîđěŕöčč ęëĺňęč ăđóďďčđóţňń˙ â ęëŕńňĺđű č äŕëĺĺ ŕíŕëčçčđóţňń˙ ń ďîěîůüţ číňĺđŕęňčâíîăî ăđŕôč÷ĺńęîăî číňĺđôĺéńŕ (GUI), đŕçđŕáîňŕííîăî Kåre Bævre čç Íŕöčîíŕëüíîăî číńňčňóňŕ çäđŕâîîőđŕíĺíč˙ Íîđâĺăčč (National Institute of Health).  ďđîöĺńńĺ ŕíŕëčçŕ íŕ ýęđŕí ęîěďüţňĺđŕ âűâîä˙ňń˙ âîçěîćíűĺ âŕđčŕíňű ěĺńň đîćäĺíčé (ęŕę ďđŕâčëî, íŕçâŕíč˙ ěóíčöčďŕëčňĺňîâ), ęîňîđűĺ ďîőîćč íŕ čçîáđŕćĺíč˙ ŕíŕëčçčđóĺěîăî ęëŕńňĺđŕ, ŕ ňŕęćĺ âŕđčŕíň âîçěîćíîăî ňđŕíńęđčáčđîâŕíč˙ (cě. đčń. 1). Ďîńëĺ ýňîăî îďĺđŕňîđ äîëćĺí čńęëţ÷čňü îřčáî÷íî ńăđóďďčđîâŕííűĺ čçîáđŕćĺíč˙ č íŕćŕňü «ÎĘ» čëč čçěĺíčňü âŕđčŕíň ňđŕíńęđčáčđîâŕíč˙ îńňŕëüíűő. Ýňî äîńňŕňî÷íî ýôôĺęňčâíűé ěĺňîä đó÷íîăî óďđŕâëĺíč˙ ňđŕíńęđčáčđîâŕíčĺě ěčëëčîíîâ čçîáđŕćĺíčé, ńîäĺđćŕůčő číôîđěŕöčţ î ěĺńňĺ đîćäĺíč˙, ďîńęîëüęó ÷čńëî âŕđčŕíňîâ ňŕęčő íŕçâŕíčé â ńĺëüńęîé ěĺńňíîńňč Íîđâĺăčč îăđŕíč÷ĺíî. Äîáđîâîëüöű, ďđčâëĺ÷ĺííűĺ ę ňđŕíńęđčáčđîâŕíčţ čńňî÷íčęîâ ýňčě ěĺňîäîě, ń÷čňŕţň, ÷ňî ýňîň ďđîöĺńń ňŕęćĺ óâëĺęŕňĺëĺí, ęŕę č đŕçăŕäűâŕíčĺ Ńóäîęó, íî â îňëč÷čĺ îň Ńóäîęó, ňđŕíńęđčáčđîâŕíčĺ čěĺĺň ĺůĺ č áîëüřîĺ ďđŕęňč÷ĺńęîĺ çíŕ÷ĺíčĺ.
Đčń. 1. Ăđŕôč÷ĺńęčé číňĺđôĺéń äë˙ đĺäŕęňčđîâŕíč˙ čçîáđŕćĺíčé ń đóęîďčńíűě ňĺęńňîě ěĺńň đîćäĺíč˙
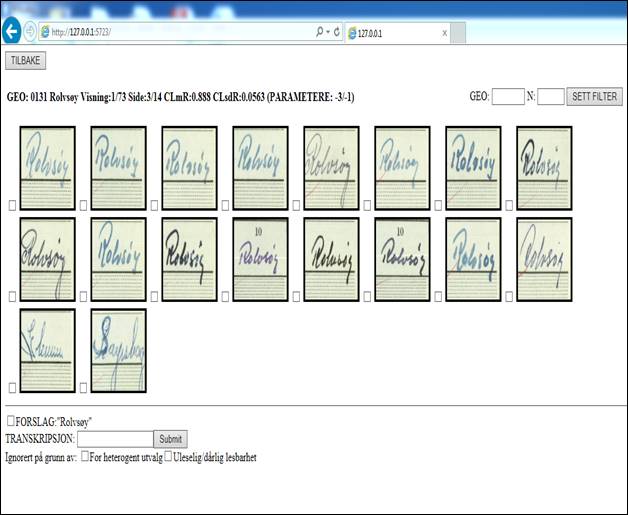
Ę ńîćŕëĺíčţ, číôîđěŕöč˙ î äŕňĺ đîćäĺíč˙ çŕíîńčëŕńü â î÷ĺíü ěĺëęčĺ ęëĺňęč ôîđěű ďĺđĺďčńč, č ěĺńňŕ äë˙ ňîăî ÷ňîáű âďčńŕňü äĺíü, ěĺń˙ö č ăîä đîćäĺíč˙ áűëî íĺäîńňŕňî÷íî. Ďîńęîëüęó ŕâňîěŕňč÷ĺńęč ňđŕíńęđčáčđîâŕňü ýňó číôîđěŕöčţ îęŕçŕëîńü íĺâîçěîćíî, ďđčřëîńü ńäĺëŕňü ýňî âđó÷íóţ, îďëŕňčâ óńëóăč číäčéńęîé ęîěďŕíčč Suntech. Ďĺđĺäŕ÷ŕ â Číäčţ čçîáđŕćĺíčé, ńîäĺđćŕůčő číôîđěŕöčţ î äŕňĺ đîćäĺíč˙, íĺ ˙âë˙ëŕńü íŕđóřĺíčĺě çŕęîíŕ î çŕůčňĺ ďĺđńîíŕëüíűő äŕííűő, ďîńęîëüęó îíč íčęŕę íĺ ěîăëč áűňü ńâ˙çŕíű ń ęîíęđĺňíűěč ďĺđńîíŕěč. Ńďóńň˙ ÷ĺňűđĺ ěĺń˙öŕ Suntech âĺđíóëč ňŕáëčöű ń îňôîđěŕňčđîâŕííűěč äŕňŕěč đîćäĺíč˙ â řĺńňčçíŕ÷íîě čëč âîńüěčçíŕ÷íîě ôîđěŕňĺ. Âűáîđî÷íűĺ ďđîâĺđęč ďîęŕçŕëč, ÷ňî ňî÷íîńňü čő ňđŕíńęđčáčđîâŕíč˙ íŕőîäčňń˙ â ďđĺäĺëŕő äîďóńňčěîé ďîăđĺříîńňč — 3%, č îáíŕđóćĺííűĺ íĺńîîňâĺňńňâč˙ ÷ŕńňî ńâ˙çŕíű ń ďđîáëĺěîé íĺęîđđĺęňíîăî çŕíĺńĺíč˙ ýňîé číôîđěŕöčč â čńňî÷íčęĺ (cě. đčń. 2).
Đčń. 2. Ďđčěĺđ ďđîáëĺěíîé çŕďčńč äŕňű đîćäĺíč˙ â čńňî÷íčęĺ

Ěű ěîćĺě ńăđóďďčđîâŕňü č čçîáđŕćĺíč˙ ń číôîđěŕöčĺé îá čěĺíŕő ďî ňŕęîěó ćĺ ďđčíöčďó, ďî 30 őŕđŕęňĺđčńňčęŕě, č ďđčěĺíčňü ăđŕôč÷ĺńęčé číňĺđôĺéc GUI äë˙ čő ňđŕíńęđčďöčč, ňŕę ćĺ, ęŕę č â ńëó÷ŕĺ ń ěĺńňŕěč đîćäĺíčé. Îäíŕęî čäĺíňč÷íűĺ čěĺíŕ, âńňđĺ÷ŕţňń˙ â čńňî÷íčęĺ ăîđŕçäî đĺćĺ, ÷ĺě íŕçâŕíč˙ ěóíčöčďŕëčňĺňîâ. Ĺůĺ đĺćĺ âńňđĺ÷ŕţňń˙ čäĺíňč÷íűĺ ęîěáčíŕöčč, ńîńňî˙ůčĺ čç čěĺíč č ôŕěčëčč. Ďîýňîěó, ďđĺćäĺ ÷ĺě čńďîëüçîâŕňü GUI íĺîáőîäčěî ďđîăíŕňü čçîáđŕćĺíč˙ ń čěĺíŕěč ÷ĺđĺç ďđîăđŕěěó Analyseform, äë˙ âűäĺëĺíč˙ ńŕěîńňî˙ňĺëüíűő ýëĺěĺíňîâ ńëîćíűő čěĺí. Íî č îíŕ, â ĺĺ íŕńňî˙ůĺě âŕđčŕíňĺ, íĺ ńđŕáŕňűâŕĺň ďî÷ňč â 20 ďđîöĺíňŕő ńëó÷ŕĺâ.  đĺçóëüňŕňĺ, äŕćĺ ďîńëĺ đŕçäĺëĺíč˙ čěĺí íŕ îňäĺëüíűĺ ÷ŕńňč čő ňđŕíńęđčďöč˙ ń ďđčěĺíĺíčĺě číňĺđŕęňčâíîăî číňĺđôĺéńŕ GUI ˙âë˙ĺňń˙ áîëĺĺ ňđóäîĺěęîé č âđĺě˙ çŕňđŕňíîé, ÷ĺě ňđŕíńęđčďöč˙ ňŕęîăî ćĺ ęîëč÷ĺńňâŕ äîęóěĺíňîâ ń ěĺńňŕěč đîćäĺíčé. Ďîýňîěó íŕě ďđčřëîńü đŕçđŕáîňŕňü ŕëüňĺđíŕňčâíűé âŕđčŕíň ňđŕíńęđčďöčč ëč÷íűő čěĺí, čńďîëüçó˙ ěĺňîä óńňŕíîâëĺíč˙ ńâ˙çĺé ěĺćäó çŕďčń˙ěč (record linkage).
Óńňŕíîâëĺíčĺ ńâ˙çĺé ěĺćäó çŕďčń˙ěč
Ó íŕń ĺńňü äîńňóď ę íîěčíŕňčâíîé číôîđěŕöčč Öĺíňđŕëüíîăî đĺĺńňđŕ íŕńĺëĺíč˙ Íîđâĺăčč 1964 ă., ďĺđĺďčńč 1960 ă. č Đĺĺńňđŕ ďđč÷čí ńěĺđňč, íŕ÷číŕ˙ ń 1951 ă. Âěĺńňĺ ýňč čńňî÷íčęč ńîäĺđćŕň čěĺíŕ, äŕňű đîćäĺíč˙ č ň. ä. ďđŕęňč÷ĺńęč äë˙ âńĺăî íŕńĺëĺíč˙ Íîđâĺăčč â 1950 ă., ďîńęîëüęó ýěčăđŕöč˙ â ňî âđĺě˙ áűëŕ î÷ĺíü íĺçíŕ÷čňĺëüíîé. Đŕçóěĺĺňń˙, îňäĺëüíűĺ ëčöŕ íĺ ěîăóň áűňü ňî÷íî čäĺíňčôčöčđîâŕíű íŕ îńíîâĺ čěĺí č äŕň đîćäĺíč˙, ňđŕíńęđčáčđîâŕííűő â Číäčč, čńęëţ÷ĺíčĺ ńîńňŕâë˙ţň đĺäęčĺ ńëó÷ŕč, ęîăäŕ â ńĺěüĺ đîćäŕëčńü áëčçíĺöű. Ŕ âîň ďŕđű čëč ăđóďďű ëčö, ďđîćčâŕâřčő âěĺńňĺ, čäĺíňčôčöčđîâŕňü âîçěîćíî. Íŕ ďĺđâîě ýňŕďĺ ěű âű˙âčëč âńĺ ńĺěüč, çŕđĺăčńňđčđîâŕííűĺ â ďĺđĺďčńč 1950 ă., ăäĺ čěĺëîńü őîň˙ áű äâŕ ÷ĺëîâĺęŕ, ÷üč äíč đîćäĺíč˙ ńîâďŕäŕëč ń äí˙ěč đîćäĺíčé äâóő ëţäĺé â ńĺěü˙ő čç ďĺđĺďčńč íŕńĺëĺíč˙ 1960 ăîäŕ čëč Đĺĺńňđŕ íŕńĺëĺíč˙ 1964 ă. Čńďîëüçó˙ ýňč ńîîňâĺňńňâč˙ â čěĺíŕő č äŕňŕő (čńęëţ÷ŕ˙ ńëó÷ŕč ń äâîéíűěč čěĺíŕěč), ěű ďîëó÷čëč ďĺđâűé ďđĺäďîëîćčňĺëüíűé âŕđčŕíň ďđî÷ňĺíč˙ čçîáđŕćĺíčé čěĺí â ďĺđĺďčńč 1950 ă. Âńĺăî ňŕęčő îęŕçŕëîńü 394 000 čçîáđŕćĺíčé, čěĺíŕ â ęîňîđűő áűëč ďđîâĺđĺíű íŕ ńîîňâĺňńňâčĺ ń ďîěîůüţ âńĺ ňîăî ćĺ ăđŕôč÷ĺńęîăî číňĺđôĺéńŕ GUI. 353 000 čç ýňčő čçîáđŕćĺíčé ńîäĺđćŕëč îäíî čç 555 đŕçëč÷íűő čěĺí, íĺęîňîđűĺ čç ýňčő čěĺí ďîâňîđ˙ëčńü äî ńîňíč đŕç. Ňŕęčě îáđŕçîě, ďđčĺě îáúĺäčíĺííîăî ŕíŕëčçŕ íŕďčńŕííűő îň đóęč č íŕďĺ÷ŕňŕííűő čěĺí óńęîđ˙ĺň ďđîöĺńń ęëŕńňĺđíîăî ňđŕíńęđčáčđîâŕíč˙ čěĺí (cě. pčń. 3).
Đčń. 3. Ăđŕôč÷ĺńęčé číňĺđôĺéń äë˙ đĺäŕęňčđîâŕíč˙ čçîáđŕćĺíčé ń đóęîďčńíűě č ďĺ÷ŕňíűě ňĺęńňîě čç đŕçíîâđĺěĺííűő čńňî÷íčęîâ
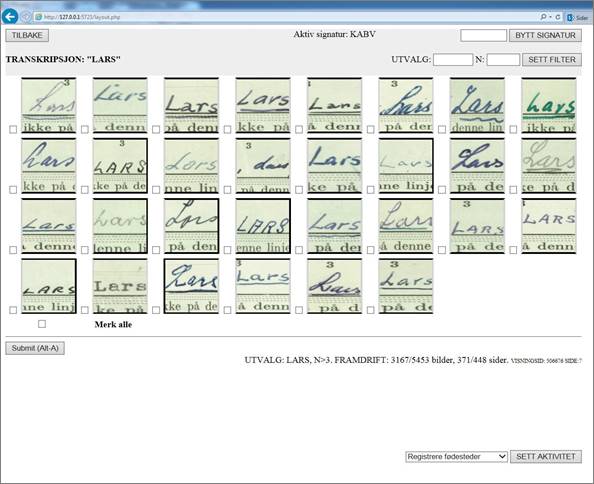
Ńëĺäó˙ číńňđóęöčč, îďĺđŕňîđű îáúĺäčí˙ţň â îäčí ęëŕńňĺđ čěĺíŕ, íŕďčńŕíčĺ ęîňîđűő íĺńęîëüęî îňëč÷ŕĺňń˙, íŕďđčěĺđ, «Niels» č «Nils», čëč «Olav» č «Olaf»; ďîńęîëüęó ňŕęčĺ ăđŕôĺěű ÷ŕńňî ńěĺřčâŕţňń˙ â đĺŕëüíîé ďđŕęňčęĺ. Ń äđóăîé ńňîđîíű, îíč íĺ äîëćíű îáúĺäčí˙ňü ňŕęčĺ čěĺíŕ, ęŕę «Maria» č «Marie», ďîőîćčĺ â íŕďčńŕíčč, íî ńîâĺđřĺííî đŕçëč÷íűĺ. Ęđîěĺ ňîăî, čç ďđîöĺńńŕ ęëŕńňĺđíîăî ŕíŕëčçŕ čńęëţ÷ŕţňń˙ čçîáđŕćĺíč˙, â ęîňîđűő îęŕçűâŕţňń˙ ńîĺäčíĺíű ýëĺěĺíňű đŕçíűő čěĺí. Âńĺ ďîäîáíűĺ ńëó÷ŕč áóäóň ňđŕíńęđčáčđîâŕíű ďîńëĺ îáđŕáîňęč îáíîâëĺííîé âĺđńčĺé ďđîăđŕěěű đŕçäĺëĺíč˙ čěĺí, đŕáîňŕ íŕä óëó÷řĺíčĺě ęîňîđîé ŕęňčâíî âĺäĺňń˙ ń ďîěîůüţ ěĺňîäîâ ěŕřčííîăî îáó÷ĺíč˙.
Ďđîđűâ â äĺëĺ đŕńďîçíŕâŕíč˙ čçîáđŕćĺíčé ďđîčçîřĺë â ńâ˙çč ń čńďîëüçîâŕíčĺě číńňđóěĺíňŕđč˙ íĺéđîńĺňĺâűő ňĺőíîëîăčé ăëóáîęîăî îáó÷ĺíč˙ ěŕřčí íîâîăî ďîęîëĺíč˙ [5]. 353 000 đŕńďîçíŕííűő ěŕřčíîé čçîáđŕćĺíčé čńďîëüçîâŕëčńü äë˙ îáó÷ĺíč˙ čńęóńńňâĺííîé íĺéđîííîé ńĺňč (ČÍŃ), ęëŕńńčôčöčđóţůĺé čěĺíŕ. Çŕňĺě ýňó îáó÷ĺííóţ ČÍŃ ďđčěĺíčëč äë˙ ęëŕńńčôčęŕöčč îńňŕâřčőń˙ 3,4 ěčëëčîíîâ íĺ čäĺíňčôčöčđîâŕííűő čěĺí â ďĺđĺďčńč. Ńĺňü ďđĺäëîćčëŕ 10 íŕčáîëĺĺ âĺđî˙ňíűő čěĺí, ęŕćäîĺ ń îďđĺäĺëĺííűě ÷čńëîě áŕëëîâ ńîîňâĺňńňâč˙. Îíč ńíîâŕ áűëč ďđîâĺđĺíű óćĺ âđó÷íóţ íŕ îńíîâĺ ňîăî ćĺ ăđŕôč÷ĺńęîăî číňĺđôĺéńŕ GUI, ÷ňî č ďđĺćäĺ. Çŕäŕ÷ŕ áűëŕ óďđîůĺíŕ çŕ ń÷ĺň čäĺíňčôčęŕöčč â ďĺđâóţ î÷ĺđĺäü ëčö ń óíčęŕëüíűě äíĺě đîćäĺíč˙ č čěĺíĺě, çŕđĺăčńňđčđîâŕííűő â îďđĺäĺëĺííîě ěĺńňĺ, íŕ ďđĺäěĺň ňîăî ďîäőîäčň ëč îäíî čç 10 čěĺí, ďđĺäëîćĺííűő čńęóńńňâĺííűě číňĺëëĺęňîě. Ń ó÷ĺňîě íĺęîňîđűő äîďîëíčňĺëüíűő ęđčňĺđčĺâ áűëč čäĺíňčôčöčđîâŕíű čěĺíŕ â ĺůĺ 450 000 čçîáđŕćĺíčé. Ýňčěč č äđóăčěč ďîäîáíűěč ěĺňîäŕěč ěîćíî çíŕ÷čňĺëüíî ńîęđŕňčňü ďđîöĺńń ňđŕíńęđčďöčč 3,4 ěčëëčîíŕ ëč÷íűő čěĺí ëţäĺé, çŕđĺăčńňđčđîâŕííűő â ďĺđĺďčńč. Ŕíŕëîăč÷íűĺ ěĺňîäű ěîăóň áűňü čńďîëüçîâŕíű â đŕńďîçíŕâŕíčč âňîđűő čěĺí č äŕćĺ ôŕěčëčé, őîň˙, ó÷čňűâŕ˙ ňî, ÷ňî âŕđčŕíňîâ ôŕěčëčé çíŕ÷čňĺëüíî áîëüřĺ, ÷ĺě ëč÷íűő čěĺí, óńčëčé íŕ čő ňđŕíńęđčáčđîâŕíčĺ ďîňđĺáóĺňń˙ áîëüřĺ. Čńęóńńňâĺííűé číňĺëëĺęň ěîćĺň îáó÷ŕňüń˙, čńďîëüçó˙ čçîáđŕćĺíč˙, â ęîňîđűő óćĺ óäŕëîńü čäĺíňčôčöčđîâŕňü čěĺíŕ, ńâ˙çŕâ čő ń äŕňŕěč đîćäĺíčé, ęŕę îďčńŕíî âűřĺ. ×ĺě áîëüřĺ čńęóńńňâĺííŕ˙ íĺéđîííŕ˙ ńĺňü îáó÷ŕĺňń˙, ňĺě ëó÷řĺ đŕáîňŕĺň ĺĺ číňĺëëĺęň, ÷ňî, â čňîăĺ, ńîęđŕůŕĺň íĺîáőîäčěîńňü ďđîâĺäĺíč˙ ňđŕíńęđčáčđîâŕíč˙ čëč ďđîâĺđęč đĺçóëüňŕňîâ âđó÷íóţ.
Îáó÷ĺííűĺ íĺéđîííűĺ ńĺňč ěîăóň čńďîëüçîâŕňüń˙ äë˙ îáđŕáîňęč ňĺęńňŕ č ęîäîâ čç äđóăčő ęëĺňîę ôîđěóë˙đŕ ďĺđĺďčńč, ńî ńâĺäĺíč˙ěč î ďîëĺ, ńĺěĺéíîě ďîëîćĺíčč č ěĺńňĺ ďđîćčâŕíč˙. Äë˙ ýňîăî íĺîáőîäčěî ńîçäŕňü îáó÷ŕţůóţ ďđîăđŕěěó, îáó÷čňü čńęóńńňâĺííóţ íĺéđîííóţ ńĺňü, čńďîëüçîâŕňü ĺĺ äë˙ ęëŕńńčôčęŕöčč čçîáđŕćĺíčé č, íŕęîíĺö, âđó÷íóţ ďđîâĺđčňü ďđîâĺäĺííóţ ĺţ ęëŕńńčôčęŕöčţ. Ďđč ýňîě âńĺ ÷čńëŕ â ďĺđĺďčńč ńíŕ÷ŕëŕ đŕçäĺë˙ţňń˙ íŕ îňäĺëüíűĺ öčôđű, çŕňĺě čńęóńńňâĺííűé číňĺëëĺęň ďđîâîäčň čäĺíňčôčęŕöčţ ęŕćäîé öčôđű, čńďîëüçó˙ ńóůĺńňâóţůčĺ äîâîëüíî ýôôĺęňčâíűĺ ěĺňîäű đŕńďîçíŕâŕíč˙ öčôđ, çŕďčńŕííűő âđó÷íóţ. Ýňîň ěĺňîä îńîáĺííî ďđîäóęňčâĺí, ęîăäŕ čçâĺńňíî ňî÷íîĺ ęîëč÷ĺńňâî öčôđ, ńîäĺđćŕůčőń˙ â ęŕćäîé ęëĺňęĺ ôîđěóë˙đŕ, ďîńęîëüęó áîëüřŕ˙ ÷ŕńňü îřčáîę ďî˙âë˙ĺňń˙ čç-çŕ íĺâĺđíîăî đŕçäĺëĺíč˙ ÷čńĺë íŕ îňäĺëüíűĺ öčôđű. Äë˙ äđóăčő ęëĺňîę ôîđěóë˙đŕ, íŕďđčěĺđ, ń číôîđěŕöčĺé îá îńíîâíîě çŕí˙ňčč, ňđóäíĺĺ čńďîëüçîâŕňü ěĺňîä îáó÷ĺíč˙ ěŕřčí ń čńęóńńňâĺííűě číňĺëëĺęňîě, ďîńęîëüęó äë˙ ęŕćäîăî âŕđčŕíňŕ çŕí˙ňč˙ íĺäîńňŕňî÷íî ňĺńňîâűő äŕííűő.
Ďĺđĺďčńü 1950 ă. áóäĺň âęëţ÷ĺíŕ â Čńňîđč÷ĺńęčé đĺĺńňđ íŕńĺëĺíč˙ Íîđâĺăčč (Historical Population Register for Norway), äë˙ ÷ĺăî íĺîáőîäčěî ńîőđŕíčňü č đŕńřčđčňü óćĺ óńňŕíîâëĺííűĺ ńâ˙çč ń Öĺíňđŕëüíűě đĺĺńňđîě íŕńĺëĺíč˙ 1964 ă., ďĺđĺďčń˙ěč 1960 č 1910 ă. č Đĺĺńňđîě ďđč÷čí ńěĺđňč 1951–1964 ă.  ďđîöĺńńĺ ďđčěĺíĺíč˙, îďčńŕííîăî âűřĺ ěĺňîäŕ ňđŕíńęđčáčđîâŕíč˙ ëč÷íűő čěĺí ęŕę đŕç óńňŕíŕâëčâŕţňń˙ ńâ˙çč ěĺćäó äŕííűěč đŕçëč÷íűő đĺĺńňđîâ.  ďđîöĺńńĺ đŕáîňű óńčëč˙ íŕďđŕâëĺíű íŕ óńňŕíîâëĺíčĺ ęŕę ěîćíî áîëüřĺăî ÷čńëŕ ńâ˙çĺé ěĺćäó çŕďčń˙ěč íŕ îńíîâŕíčč äŕííűő î äŕňĺ đîćäĺíč˙, čěĺíč č, ĺńëč ňŕęîâűĺ čěĺţňń˙, ěĺńňĺ đîćäĺíč˙/ďđîćčâŕíč˙. Ďîęŕ ďĺđĺďčńč 1920 č 1930 ă. îńňŕţňń˙ íĺäîńňóďíű čç-çŕ çŕęîíŕ îá îőđŕíĺ ďĺđńîíŕëüíűő äŕííűő, ěîćíî ńâ˙çŕňü äŕííűĺ áîëĺĺ đŕííĺé ďĺđĺďčńč 1910 ă. Ýňî ďĺđâŕ˙ íîđâĺćńęŕ˙ ďĺđĺďčńü, đĺăčńňđŕöčîííűĺ ëčńňű ęîňîđîé âęëţ÷ŕëč íĺ âîçđŕńň, ŕ äŕňó đîćäĺíč˙ äë˙ âńĺăî íŕńĺëĺíč˙ ńňđŕíű.  1891 č 1900 ă. äŕňű đîćäĺíč˙ îňěĺ÷ŕëčńü ňîëüęî äë˙ äĺňĺé ěëŕäřĺ äâóő ëĺň.
Äîďîëíčňĺëüíűĺ őŕđŕęňĺđčńňčęč äë˙ óńňŕíîâëĺíč˙ ńâ˙çĺé ěĺćäó çŕďčń˙ěč
 äŕëüíĺéřĺé ďđčâ˙çęĺ çŕďčńĺé ěîćíî čńďîëüçîâŕňü ôŕěčëčč č âňîđűĺ čěĺíŕ, ăđóďďčđó˙ čő â ęëŕńňĺđű č ńđŕâíčâŕ˙ ń čěĺíŕěč â áîëĺĺ ďîçäíčő ďĺđĺďčń˙ő, ŕíŕëîăč÷íî ěĺňîäó đŕáîňű ń ëč÷íűě čěĺíĺě. Îńîáóţ ńëîćíîńňü ďđĺäńňŕâë˙ĺň čäĺíňčôčęŕöč˙ ôŕěčëčé 255 000 ćĺíůčí, ęîňîđűĺ âűřëč çŕěóć â ďĺđčîä ěĺćäó ďĺđĺďčń˙ěč 1950–1960 ă. č âç˙ëč ôŕěčëčţ ěóćŕ. Çŕęîíîäŕňĺëüńňâî ňîăî âđĺěĺíč đĺäęî äîďóńęŕëî číűĺ ďîâîäű äë˙ čçěĺíĺíč˙ čěĺí, íî ňĺ, ó ęîăî áűëč äâîéíűĺ čěĺíŕ ěîăëč íŕ÷ŕňü čńďîëüçîâŕňü âňîđîĺ čě˙ â ęŕ÷ĺńňâĺ îńíîâíîăî[3]. Ę ńîćŕëĺíčţ, ďîëĺ «ďđĺäűäóůĺĺ čě˙» đĺäęî çŕďîëí˙ĺňń˙ â Öĺíňđŕëüíîě đĺĺńňđĺ íŕńĺëĺíč˙, č ó ďđčěĺđíî ďîëîâčíű íŕńĺëĺíč˙ číôîđěŕöč˙ î đîäčňĺë˙ő â äŕííîě čńňî÷íčęĺ ňŕęćĺ íĺ óęŕçŕíŕ.
Ďĺđĺ÷čńëĺííűĺ âűřĺ ďĺđĺěĺííűĺ ˙âë˙ţňń˙ îńíîâíűěč, â ďđîöĺńńĺ óńňŕíîâëĺíč˙ ńâ˙çĺé ěĺćäó çŕďčń˙ěč ďĺđĺďčńč 1950 ă. ęŕę ń áîëĺĺ đŕííčěč, ňŕę č áîëĺĺ ďîçäíčěč íîěčíŕňčâíűěč čńňî÷íčęŕěč. Ęđîěĺ ňîăî, číôîđěŕöč˙ î ďîëîâîé ďđčíŕäëĺćíîńňč ŕâňîěŕňč÷ĺńęč ń÷čňűâŕĺňń˙ čç čńňî÷íčęŕ č ďîňîě ńđŕâíčâŕĺňń˙ íŕ ńîîňâĺňńňâčĺ ń čěĺíĺě â ďĺđĺďčńč. Ĺńňĺńňâĺííî, ĺńëč äîáŕâčňü äîďîëíčňĺëüíűĺ ďĺđĺěĺííűĺ: ńĺěĺéíîĺ ďîëîćĺíčĺ, îňíîřĺíčĺ ę ăëŕâĺ ńĺěüč, ďđîôĺńńč˙, îáđŕçîâŕíčĺ č ěčăđŕöč˙, ňî ďĺđĺďčńü 1950 ă. áóäĺň ĺůĺ áîëĺĺ öĺííűě čńňî÷íčęîě äë˙ äëčňĺëüíűő ďî őđîíîëîăčč č ęđîńń-ńĺęöčîííűő čńńëĺäîâŕíčé. Čńďîëüçîâŕíčĺ ěĺňîäŕ ęëŕńňĺđčçŕöčč ďđč đŕáîňĺ ń ýňčěč ňĺęńňîâűěč ďîë˙ěč ďîňđĺáóĺň çíŕ÷čňĺëüíűő đĺńóđńîâ äë˙ ďđîâĺđęč č đĺäŕęňčđîâŕíč˙ ęëŕńňĺđîâ, č ęîäčđîâŕíč˙ číôîđěŕöčč íŕ ńëĺäóţůĺě ýňŕďĺ. Äë˙ ýňîăî ěű čńďîëüçóĺě ÷čńëîâűĺ ęîäű, ęîňîđűĺ Ńňŕňčńňč÷ĺńęîĺ óďđŕâëĺíčĺ Íîđâĺăčč ďđîńňŕâë˙ëî â ńďĺöčŕëüíűő ńňđîęŕő ôîđěóë˙đîâ ďĺđĺďčńč 1950 ă. Ďîńëĺ ýňîăî ęîäű áűëč ďđîáčňű íŕ ďĺđôîęŕđňŕő (ńě. đčń. 4) č âńĺ đĺçóëüňŕňű đŕńń÷čňŕíű ń ďîěîůüţ ýëĺęňđîěĺőŕíč÷ĺńęîăî îáîđóäîâŕíč˙. Ę ńîćŕëĺíčţ, ýňč ďĺđôîęŕđňű íĺ ńîőđŕíčëčńü, čő óíč÷ňîćčëč ÷ňîáű îńâîáîäčňü ěĺńňî äë˙ ěŕňĺđčŕëîâ ďĺđĺďčńč 1960 ă., ęîňîđŕ˙ ďđîřëŕ äî ňîăî, ęŕę Ńňŕňčńňč÷ĺńęîĺ óďđŕâëĺíčĺ Íîđâĺăčč ďĺđĺřëî íŕ čńďîëüçîâŕíčĺ íîâîăî ďîęîëĺíč˙ íîńčňĺëĺé äë˙ ęîěďŕęňíîăî őđŕíĺíč˙ číôîđěŕöčč.
Đčń. 4. Ďĺđôîęŕđňŕ, čńďîëüçîâŕííŕ˙ äë˙ ŕăđĺăŕöčč ďĺđĺďčńč 1950 ă. â Íîđâĺăčč
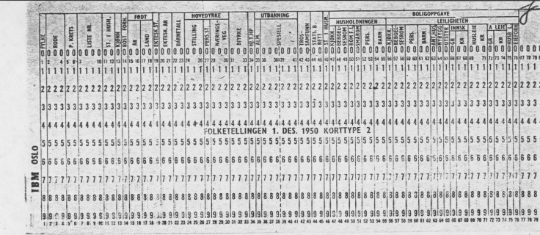
Đŕńďîçíŕâŕíčĺ ęîäîâ äîďîëíčňĺëüíűő ďĺđĺěĺííűő ďđîčçâîäčňń˙ ń ďîěîůüţ ěĺňîäîâ ěŕřčííîăî îáó÷ĺíč˙ č áčáëčîňĺ÷íűő ďđîăđŕěě. ČŇ-ńďĺöčŕëčńňű ďđčçíŕëč ýňî âîçěîćíűě, ňŕę ęŕę â ďđîöĺńńĺ ęîäčđîâŕíč˙ ěŕňĺđčŕëîâ ďĺđĺďčńč 1950 ă. ďđčíčěŕëî ó÷ŕńňčĺ âńĺăî íĺńęîëüęî ńîňđóäíčęîâ ńňŕňóďđŕâëĺíč˙ Íîđâĺăčč. Ęîäű ďđîńňŕâë˙ëč ęđŕńíűě ęŕđŕíäŕřîě, ďîýňîěó îíč őîđîřî đŕçëč÷čěű, ŕ ęîëč÷ĺńňâî âîçěîćíűő ŕëüňĺđíŕňčâ îăđŕíč÷ĺíî âî âńĺő ďîë˙ő, ęđîěĺ «îńíîâíîăî çŕí˙ňč˙». Äë˙ âűäĺëĺíč˙ č ęëŕńńčôčęŕöčč ňđĺőçíŕ÷íűő ęîäîâ, čńďîëüçîâŕííűő â ďĺđĺďčńč, ďëŕíčđóĺňń˙ čńďîëüçîâŕňü áčáëčîňĺęó ăëóáîęîăî îáó÷ĺíč˙ Tensorflow. Áčáëčîňĺęč ýňîăî ęëŕńńŕ äŕţň âîçěîćíîńňü čńďîëüçîâŕňü ńîâđĺěĺííűĺ ňĺőíîëîăčč îáđŕáîňęč čçîáđŕćĺíčé íŕ ěîůíűő ăđŕôč÷ĺńęčő ďđîöĺńńîđŕő óđîâí˙ GPU.
Ďëŕíčđóĺňń˙ čńďîëüçîâŕňü äâŕ ďîäőîäŕ. Ďĺđâűé ďîäőîä âęëţ÷ŕĺň îáó÷ĺíčĺ ďđîăđŕěěű ń čńďîëüçîâŕíčĺě ńĺňŕ äŕííűő, ńîńňî˙ůĺăî čç ňđĺőçíŕ÷íîăî ÷čńëŕ-ęîäŕ č ŕííîňŕöčé čç ńĺňŕ đóęîďčńíűő ÷čńĺë mnist (http://yann.lecun.com/exdb/mnist/). Ŕíŕëîăč÷íűé ďîäőîä áűë čńďîëüçîâŕí äë˙ đŕńďîçíŕâŕíč˙ 5-çíŕ÷íűő ÷čńĺë (https://github.com/thomalm/svhn-multi-digit), ďđč ýňîě ňî÷íîńňü đĺçóëüňŕňîâ, ďîëó÷ĺííűő äë˙ îäíîçíŕ÷íűő ÷čńĺë (99,7%) ńíčçčëŕńü äî 96,5% (https: // github.com/thomalm/svhn-multi-digit/blob/master/04-mnist-synthetic-model.ipynb). Äë˙ ďîâűřĺíč˙ ňî÷íîńňč đĺçóëüňŕňŕ â íŕńňî˙ůĺĺ âđĺě˙ ńîçäŕĺňń˙ äîďîëíčňĺëüíűé îáó÷ŕţůčé ńĺň, îńíîâŕííűé íŕ đĺďđĺçĺíňŕňčâíîé âűáîđęĺ ÷čńĺë čç ôîđě ďĺđĺďčńč. Âňîđîé ďîäőîä ďđĺäóńěŕňđčâŕĺň ŕíŕëčç îňäĺëüíűő öčôđ. Ę ńîćŕëĺíčţ, ýňîň ěĺňîä đŕáîňű ń çŕęîäčđîâŕííîé číôîđěŕöčĺé íĺ óäŕńňń˙ ďđčěĺíčňü ďđč ňđŕíńęđčáčđîâŕíčč ěŕňĺđčŕëîâ ďĺđĺďčńč 1930 ă., ďîńęîëüęó ęîäű áűëč ďđîďčńŕíű íŕ îňäĺëüíűő ëčńňŕő, ęîňîđűĺ íĺ ńîőđŕíčëčńü. ×ňî ęŕńŕĺňń˙ ďĺđĺďčńč 1950 ăîäŕ, ňî ĺĺ ěŕňĺđčŕëű, ďî âńĺě îńíîâíűě őŕđŕęňĺđčńňčęŕě â öĺëîě óäŕĺňń˙ đŕńřčôđîâűâŕňü ń ďîěîůüţ ěĺňîäîâ ďîëóŕâňîěŕňč÷ĺńęîăî ňđŕíńęđčáčđîâŕíč˙. Îńíîâíűěč çŕäŕ÷ŕěč ďî-ďđĺćíĺěó îńňŕţňń˙ ďîčńę ěĺňîäîâ č ŕëăîđčňěîâ, ęîňîđűĺ îďňčěŕëüíî ďîäáčđŕţň ńâ˙çč ěĺćäó đŕçëč÷íűěč ďĺđĺěĺííűěč č đŕöčîíŕëčçŕöč˙ ěĺňîäîâ číňĺđŕęňčâíîé ęîđđĺęňóđű. Ěű ăîňîâű ę ńîňđóäíč÷ĺńňâó ńî âńĺěč, ęňî çŕíčěŕĺňń˙ ňđŕíńęđčáčđîâŕíčĺě č čńďîëüçîâŕíčĺě äŕííűő íîěčíŕňčâíűő čńňî÷íčęîâ [6], ďîńęîëüęó îďčńŕííűĺ çäĺńü ěĺňîäű áóäóň ňŕęćĺ ďîëĺçíű äë˙ ňđŕíńęđčáčđîâŕíč˙ ěĺňđč÷ĺńęčő ęíčă, çŕďčńĺé ÇŔĂŃîâ č äđóăčő äîęóěĺíňîâ ó÷ĺňŕ íŕńĺëĺíč˙.
[1] Ďóáëčęŕöčč, îńíîâŕííűĺ íŕ ěŕňĺđčŕëŕő ďĺđĺďčńč 1950 ă., â ňîě ÷čńëĺ íŕ ŕíăëčéńęîě ˙çűęĺ, äîńňóďíű ďî ŕäđĺńó: http://ssb.no/a/folketellinger/. Ďđîńňî íŕäî íŕćŕňü íŕ 1950 ăîä. Ęíčăŕ ń ęîäŕěč čěĺĺňń˙ ňîëüęî íŕ íîđâĺćńęîě ˙çűęĺ; číńňđóęöčč äë˙ ďĺđĺďčń÷čęîâ íŕ ŕíăëčéńęîě äîńňóďíű ďî ŕäđĺńó http://rhd.uit.no/census/ft1950E.html
[2]  đŕáîňĺ ďî ďîčńęó ěĺňîäîâ ňđŕíńęđčáčđîâŕíč˙ ďđčíčěŕëč ó÷ŕńňčĺ ňŕęćĺ Kåre Bævre čç Íîđâĺćńęîăî íŕöčîíŕëüíîăî číńňčňóňŕ çäîđîâü˙; Lars Holden čç Íîđâĺćńęîăî âű÷čńëčňĺëüíîăî öĺíňđŕ č Lars Ailo Ballo, čç Óíčâĺđńčňĺňŕ Ňđîěń¸.
[3]  ęŕ÷ĺńňâĺ «middle» — ńđĺäíĺăî čěĺíč ěîćĺň âűńňóďŕňü âňîđîĺ čě˙, äŕííîĺ ďđč đîćäĺíčč, čě˙ îňöŕ čëč äŕćĺ ôŕěčëč˙, ęîňîđűő, ęńňŕňč, ňîćĺ ěîćĺň áűňü äâĺ.
References
1. Kliatskine V. et al. A structured method for the recognition of complex historical tables // History and Computing. 1997. Vol. 9 (1–3). P. 58–77.
2. Madhvanath S. et al. Reading handwritten US census forms // Proceedings of the Third International Conference on Document Analysis and Recognition. Vol. 1. IEEE Computer Society, 1995. P. 82–85.
3. Thorvaldsen G. et al. A Tale of Two Transcriptions. Machine-Assisted Transcription of Historical Sources // Historical Life Course Studies. 2015. Vol. 2 (1). P. 1–19.
4. Torval'dsen G. T. Nominativnye istochniki v kontekste vsemirnoi istorii perepisei: Rossiya i Zapad // Izvestiya Ural'skogo federal'nogo universiteta. Seriya 2. Gumanitarnye nauki. 2016. T. 18. ą 3 (154). S. 9–28.
5. Krizhevsky A., Sutskever I., Hinton G. E. Imagenet classification with deep convolutional neural networks // Advances in neural information processing systems 25. NIPS, 2012.
6. Glavatskaya E. M., Torval'dsen G. T. Etno-religioznaya i demograficheskaya dinamika v gornoi Evrazii v kontse XIX – nachale XX vv.: proekt sozdaniya Registra naseleniya Urala // Informatsionnyi byulleten' assotsiatsii «Istoriya i komp'yuter». 2016. ą 45 (spetsvypusk). S. 251–254.
|









